Introduction
We search many things online on the internet daily to purchase something, for comparing one product with another, to decide if one product is superior to other, etc. We straight away go to the reviews to see the stars or positive feedbacks it has received, right?
In this tutorial blog we will see how to extract Amazon reviews with Python Scrapy. We will save data in the excel spreadsheet or csv. These are the data-fields we will extract:
- Review’s Title
- Ratings
- Reviewer’s Name
- Review’s Description
- Review’s Content
- Helpful Counts
Then we will do some basic analysis with Pandas on dataset that we have extracted. Here, some data cleaning would be needed and in the end, we will provide price comparisons on an easy visual chart with Seaborn and Matplotlib.
Between these two platforms, we have found Shopee harder to extract data for some reasons: (1) it has frustrating popup boxes that appear while entering the pages; as well as (2) website-class elements are not well-defined (a few elements have different classes).
For the reason, we would start with extracting Lazada first. We will work with Shopee during Part 2!
Initially, we import the required packages:
# Web Scraping from selenium import webdriver from selenium.common.exceptions import * # Data manipulation import pandas as pd # Visualization import matplotlib.pyplot as plt import seaborn as sns
It’s time to get started.
We choose Scrapy – a Python framework for larger-scale data scraping. Together with it, a few other packages would be needed to extract Amazon product reviews.
- Requests: For sending a URL request
- Pandas: For exporting csv
- Pymysql: For connecting mysql server as well as storing data there
- Math: For implementing mathematical operations
You can anytime install packages like given below with conda or pip.
pip install scrapy
OR
conda intall -c conda-forge scrapy
Let’s outline Start URL for Scraping Seller’s Links
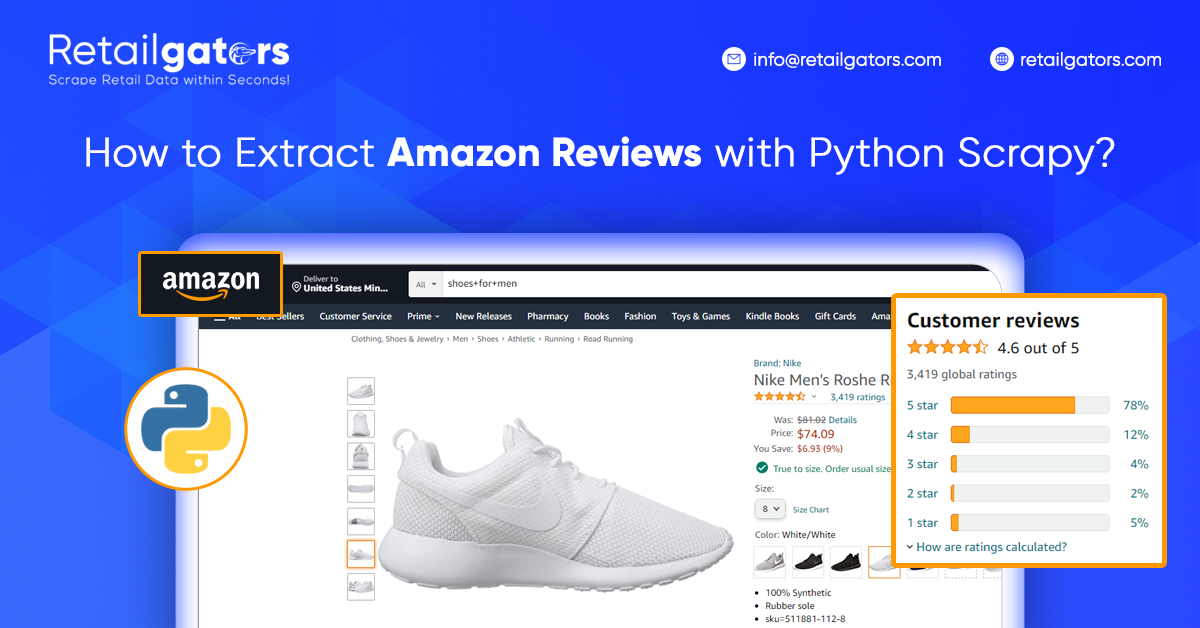
Let’s see what this will like to extract reviews for a product. We have taken the URL: https://www.amazon.com/dp/B07N9255CG This will look like this:
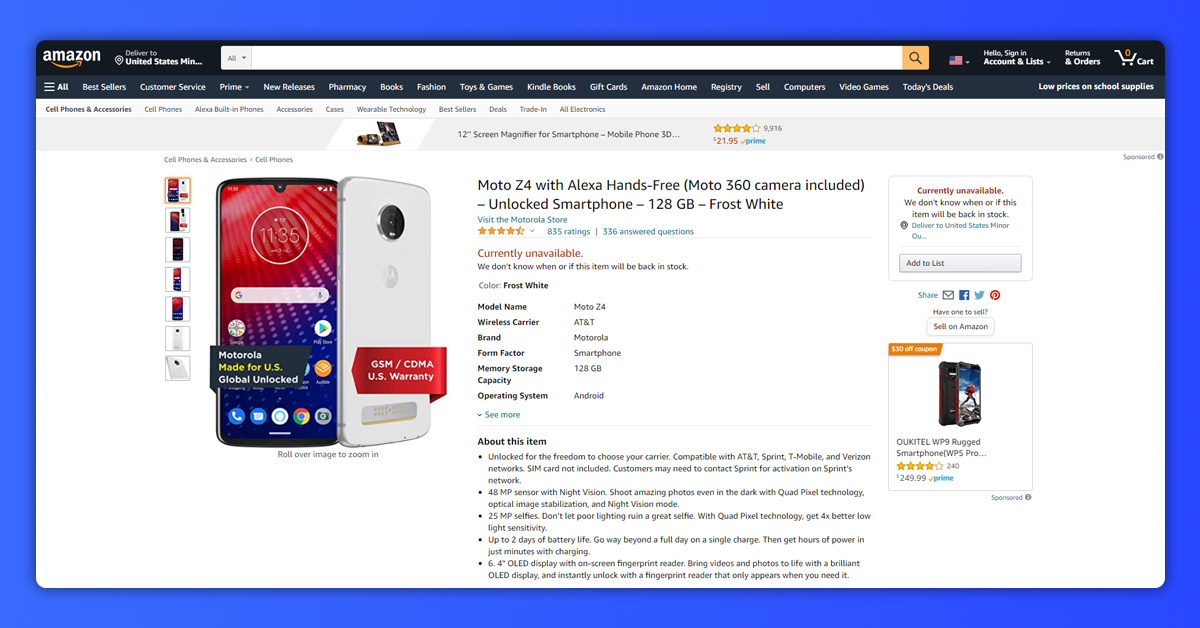
When we go to its review section, this looks like an image given below. This might have different names given in the reviews.
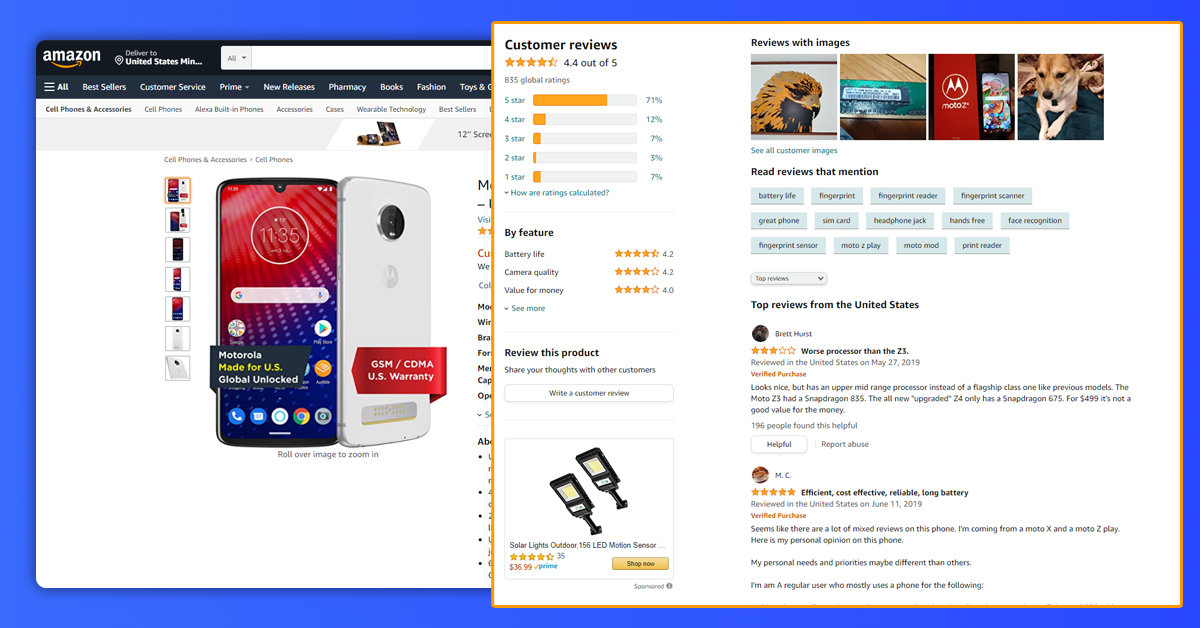
However, if you carefully inspect these requests on the back whereas loading a page as well as play a bit with next as well as previous pages of the review, you could have noticed that there’s the post request loaded having content in a page?
Here, we have looked at the payload as well as headers needed for the successful response. In case, you are having properly inspected pages, you’ll identify the change between shifting a page as well as how that reflects on requests given for that.
NEXT PAGE --- PAGE 2 https://www.amazon.com/hz/reviews-render/ajax/reviews/get/ref=cm_cr_arp_d_paging_btm_ next_2 Headers: accept: text/html,*/* accept-encoding: gzip, deflate, br accept-language: en-US,en;q=0.9 content-type: application/x-www-form-urlencoded;charset=UTF-8 origin: https://www.amazon.com referer: https://www.amazon.com/Moto-Alexa-Hands-Free-camera-included/productreviews/B07N9255CG?ie=UTF8&reviewerType=all_reviews user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36 x-requested-with: XMLHttpRequest Payload: reviewerType: all_reviews pageNumber: 2 shouldAppend: undefined reftag: cm_cr_arp_d_paging_btm_next_2 pageSize: 10 asin: B07N9255CG PREVIOUS PAGE --- PAGE 1 https://www.amazon.com/hz/reviewsrender/ajax/reviews/get/ref=cm_cr_getr_d_paging_btm_prev _1 Headers: accept: text/html,*/* accept-encoding: gzip, deflate, br accept-language: en-US,en;q=0.9 content-type: application/x-www-form-urlencoded;charset=UTF-8 origin: https://www.amazon.com referer: https://www.amazon.com/Moto-Alexa-Hands-Free-camera-included/ productreviews/B07N9255CG/ ref=cm_cr_arp_d_paging_btm_next_2? ie=UTF8&reviewerType=all_reviews& pageNumber=2 user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36 x-requested-with: XMLHttpRequest Payload: reviewerType: all_reviews pageNumber: 2 shouldAppend: undefined reftag: cm_cr_arp_d_paging_btm_next_2 pageSize: 10 asin: B07N9255CG
The Key Part: Script/CODE
You can use two ways for making a script:
- Make an entire Scrapy project
- Make a group of files in the folder for narrowing down the project size
In the past tutorial, we have showed you an entire Scrapy project as well as data to make as well as modify it. This time, we have chosen the most narrowed way possible. Yes, only a group of files as well as Amazon reviews would be there!!
We are utilizing Python and Scrapy to scrape all the Amazon reviews, it’s very easy to stay convenient and take a road for xPath.
The most significant part of xPath is capturing the pattern. As to copy similar xPath from a Google inspect window as well as paste it, this is very easy but an old-school method and not effective every time.
So, what to do? Well, we will notice xPath for the similar field, let’s say “Review Title” as well as see how that makes a pattern to minimize the xPath.
Here are two examples about a related xPath given below.
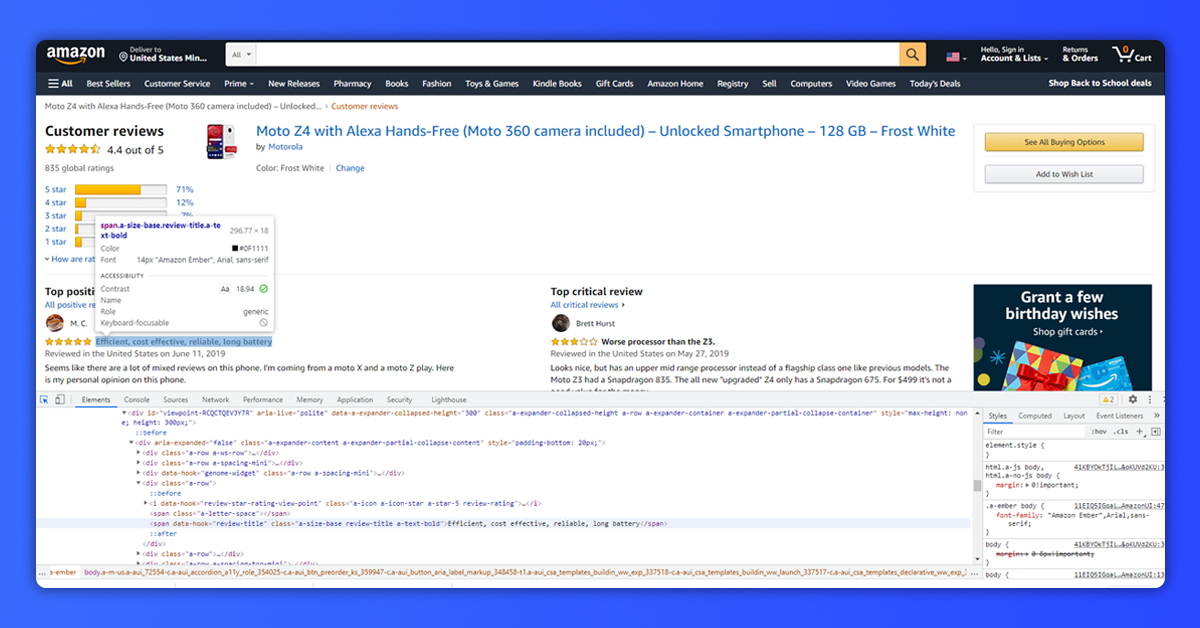
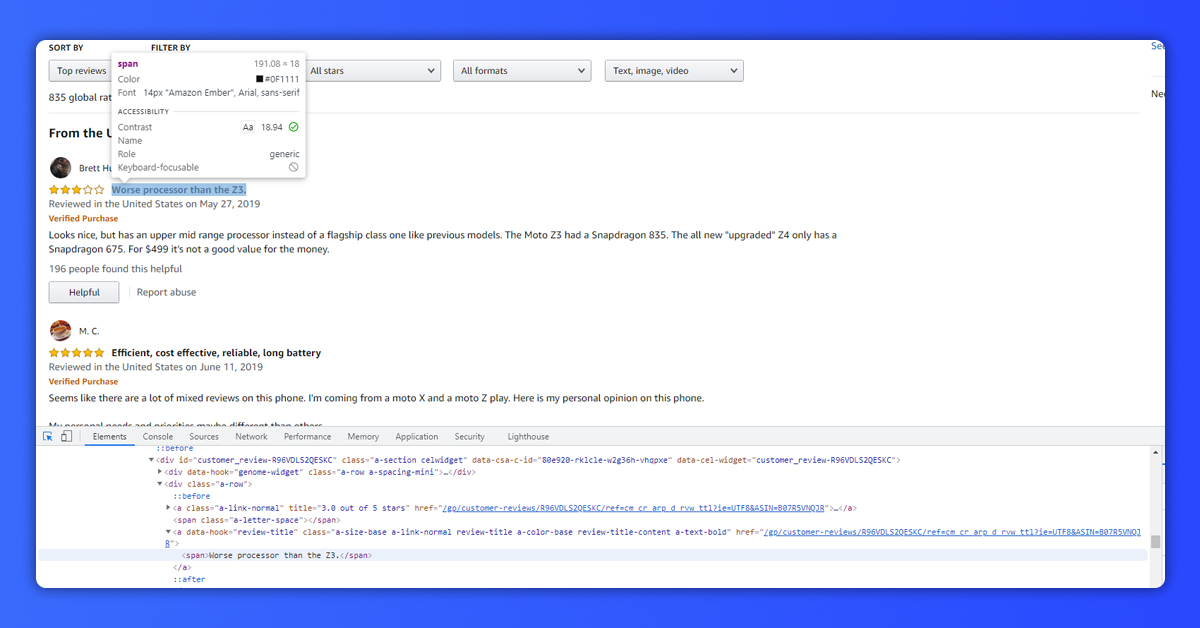
Here, you can see that many similar attributes are there to a tag that has details about a “Review Title”.
So, resulting xPath to use for a Review Title would be,
- //a[contains(@class,"review-title-content")]/span/text()
- Here, we’ve given all the xPaths for different fields that we will scrape.
- Review’s Title: //a[contains(@class,"review-title-content")]/span/text()
- Ratings: //a[contains(@title,"out of 5 stars")]/@title
- Reviewer’s Name: //div[@id="cm_cr-review_list"]//span[@class="a-profile-name"]/text()
- Review Content or Description/: //span[contains(@class,"review-text-content")]/span/text()
- Useful Count: /span[contains(@class,"cr-vote-text")]/text()
Apparently, some stripping as well as joining to end results within a few xPaths is very important to find perfect data. In addition, we need to remove additional white spaces.
It sounds good,
Now, we know how to move across pages as well as how to scrape data from them as well as time to collect those!!
Here is the entire code for scraping all the reviews for a single product!!!
import math, requests, json, pymysql
from scrapy.http import HtmlResponse
import pandas as pd
con = pymysql.connect ( 'localhost', 'root', 'password','database' )
raw_dataframe = [ ]
res = requests.get( 'https://www.amazon.com/Moto-Alexa-Hands-Free-camera-included/ product-reviews/B07N9255CG?ie=UTF8&reviewerType.all_reviews' )
response = HtmlResponse( url=res.url,body=res.content )
product_name = response.xPath( '//h1/a/text()').extract_first( default=' ' ).strip()
total_reviews = response.xPath('//span[contains(text(),"Showing")]/text()').extract_first(default='').strip().split()[-2]]
total_pages = math.ceil(int(total_reviews)/10)
for i in range(0,total_pages):
url = f"https//www.amazon.com/hz/reviews-render/ajax/reviews/get/ref=cm_crarp_d_paging_btm_next_{str(i+2)}"
head = {'accept': 'text/html, */*',
'accept-encoding': 'gzip,deflate,br',
'accept-language': 'en-US,en;q=0.9',
'content-type': 'application/x-www-form-urlencoded;charset=UTF-8', 'origin': 'https://www.amazon.com,
'referer':response.url,
'user-agent': 'Mozilla/5.0(Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KWH, like Gecko) Chrome/81.0.4044.113 Safari/537.36',
'x- requested-with': 'XMLHttpRequest'
}
payload = {'reviewerType':'all_reviews'
'pageNumber': i+2,
'shouldAppend': 'undefined',
'reftag': f'cm_crarp_d_paging_btm_next_{str(i+2))',
'pageSize': 10,
'asin': '807N9255C',
}
res = requests.post(url,headers=head,data=json.dumps(payload))
response = HtmlResponse(url=res.url, body=res.content)
loop = response.xPath('//div[contains(@class,"a-section review")]')
for part in loop:
review_title = part.xPath('.//a[contains(@Class,"review-title-content")]/span/text()').extract_first(default=' ').strip()
rating =part.xPath('.//a[contains(@title,"out of 5 stars")]/@title').extract_first(default=' ').strip().split()[0].strip()
reviewername = part.xPath('.//span[@class."a-profile-name']/text()').extract_first(default=' ').strip()
description =''.join(part. xPath('.//span[contains(@class,"review-text-content")]/span/text()') .extract()).strip()
helpful_count =part.xPath('.//span[contains(@class,"cr-vote-text")]/ text()').extract_first(default ='').strip().split()[0].strip()
raw_dataframe.append([product_name,review_title,rating,reviewer_name, description,helpful_count])
df =pd.Dataframe,(raw_dataframe,columns['Product Name','Review Title','Review Rating','Reviewer Name','Description','Helpful Count' ]),
#inserting into mySQL table
df.to_sql("review_table",if_exists='append',con=con)
#exporting csv
df.to_csv("amazon reviews.csv",index=None)
Important Points When Extracting Amazon Reviews
The entire procedure looks extremely easy to apply but there could be some problems while implementing that like response issues, captcha issues, and more. To bypass this, you need to keep a few proxies within reach so that this procedure could become a lot smoother.
At times, when a website changes the structure. In case, the scraping runs for a long, then you need to keep the error logs within your scripts or error alerts might also work as it will help you make aware when a moment structure gets changed.
Conclusion
All types of review scraping services are helpful. Why? The reasons are:
- To make a dataset that is utilized for the research for academic objective or industrial objective?
- To monitor the product views by the customers in case, you are the seller on a similar website
- To observe other sellers
If you want to scrape Amazon Reviews Data, you can contact RetailGators or ask for a free quote!




Leave a Reply
Your email address will not be published. Required fields are marked