What’s a Web Data Scraper?
We could write programs, which allow us for reading certain types of files. Those can consist of comma-separated values (.csv), text (.txt), as well as image files (.png, .bmp, .jpg). Although, a web data scraper is the application, which requires HTML coded from the site. Different HTML parsing libraries could be used for interacting with a website resource code in the stylish way.
Scraper’s Description We Have Created
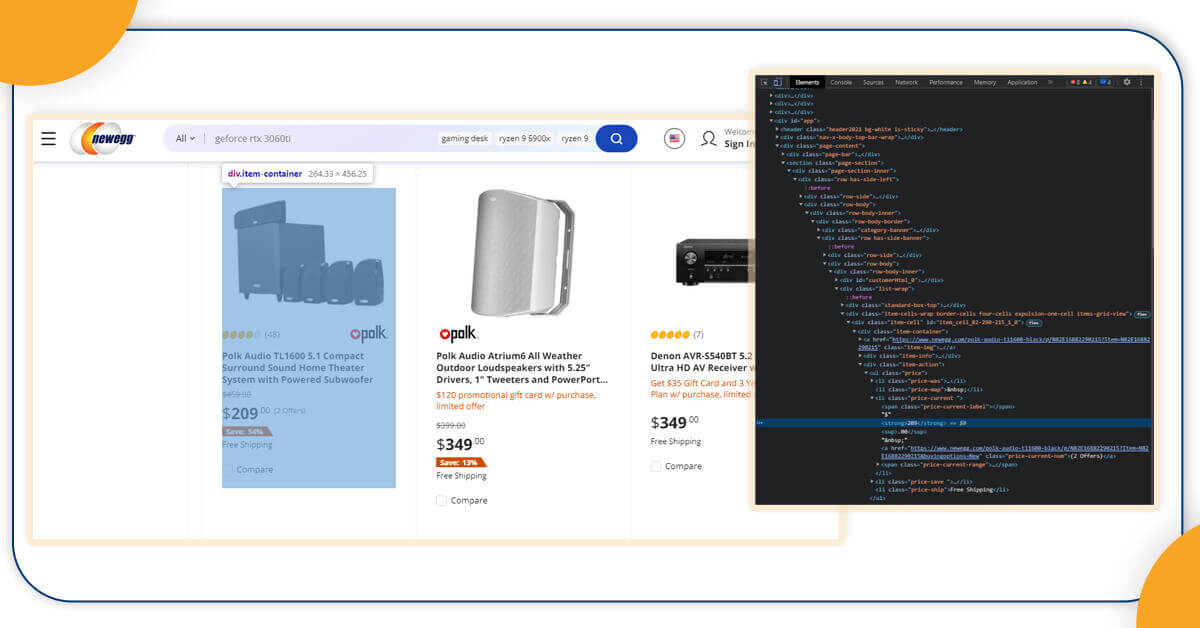
The web data scraper we have created obtains data from the Newegg site. Details like product name, brand name, as well as shipping are taken from graphics cards. We required to add the capability of scraping pricing data from all graphics cards also. This little change has led to considerable modifications in an original code. Getting pricing data have forced us to create an account for different items, which are not available in the stock. We also need to add codes to the advertisement account. If we hadn’t checked for the advertisements, then our data scraper would get lessened in its capability to get information. We would offer more data about the installments in upcoming parts of the series.
Tools Required for This Build

- Beautiful Soup
- Pip
- Python
Python is the high-level programming language (it just means this has English-like syntax). This thing you wish to create is reliant on the language, which you utilize. There are different languages, which are used for building particular things as well as others, which can be utilized to create different things. It looks that number of Python-dependent web data scraping libraries to select from are endless. So, Python is a language of option when comes to creating a web data scraper.
Pip is the Python package manager. Different programming languages have different standard libraries, which constitute the structures related with the language on the whole. Normal libraries are ones, which you could access straight (using some type of keywords to comprise libraries in the project) and ultimately (through the library getting included in the project through default). Libraries, which are not the part of a core language required to get downloaded distinctly so that you could use them within the project. Pip helps us to download outside libraries, which are not limited to Python programming language.
Beautiful Soup is the Python-based library utilized for web data scraping (this is formally named as an HTML parser). Many libraries are there, which could be used for web scraping, although, there looks to be different sources, which utilize Beautiful Soup. In case, you wish to utilize other libraries like Scrapy or Selenium then you can surely do it.
Downloading Python
Find the newest version of Python. In case, you are using a Windows machine, you would need to add a location of a core Python script towards your path location variable. Commands, which require to be scraped from a command prompt won’t work in case not done.
Download Pip
Save get-pip.py into your PC. Use a terminal for setting your directory to one, which has a file get-pip.py. When it is done, enter the command given into the terminal:
py get-pip.py
The above line will implement a code from a file as well as install pip into your PC. You may also write “python” in place of “py” in case, the given line does not work well for you. Our systems allow us to implement Python code through writing “py” in advance to the proposed file. Whatever works for your system, just use that.
Download Beautiful Soup
Write the line of code given here in your terminal for installing Beautiful Soup:
pip install bs4
You may also check a Beautiful Soup documentation to get more installation data. Whenever you are on a site, just scroll down and “Install Beautiful Soup.”
We have done here! If you want to know more, just contact Retailgators or ask for a free quote for your Newegg web scraping requirements.




Leave a Reply
Your email address will not be published. Required fields are marked