
Introduction
We have been frequently said that between two big e-commerce platforms of Malaysia (Shopee and Lazada), one is normally cheaper as well as attracts good deal hunters whereas other usually deals with lesser price sensitive.
So, we have decided to discover ourselves… in the battle of these e-commerce platforms!
For that, we have written a Python script with Selenium as well as Chrome driver for automating the scraping procedure and create a dataset. Here, we would be extracting for these:
- Product’s Name
- Product’s Name
Then we will do some basic analysis with Pandas on dataset that we have extracted. Here, some data cleaning would be needed and in the end, we will provide price comparisons on an easy visual chart with Seaborn and Matplotlib.
Between these two platforms, we have found Shopee harder to extract data for some reasons: (1) it has frustrating popup boxes that appear while entering the pages; as well as (2) website-class elements are not well-defined (a few elements have different classes).
For the reason, we would start with extracting Lazada first. We will work with Shopee during Part 2!
Initially, we import the required packages:
# Web Scraping from selenium import webdriver from selenium.common.exceptions import * # Data manipulation import pandas as pd # Visualization import matplotlib.pyplot as plt import seaborn as sns
Then, we start the universal variables which are:
- Path of a Chrome web driver
- Website URL
- Items we wish to search
webdriver_path = 'C://Users//me//chromedriver.exe' # Enter the file directory of the Chromedriver Lazada_url = 'https://www.lazada.com.my' search_item = 'Nescafe Gold refill 170g' # Chose this because I often search for coffee!
After that, we would start off the Chrome browser. We would do it with a few customized options:
# Select custom Chrome options
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('start-maximized')
options.add_argument('disable-infobars')
options.add_argument('--disable-extensions')
# Open the Chrome browser
browser = webdriver.Chrome(webdriver_path, options=options)
browser.get(Lazada_url)
Let’s go through about some alternatives. The ‘— headless’ argument helps you run this script with a browser working in its background. Usually, we would suggest not to add this argument in the Chrome selections, so that you would be able to get the automation as well as recognize bugs very easily. The disadvantage to that is, it’s less effective.
Some other arguments like ‘disable-infobars’, ‘start-maximised’, as well as ‘— disable-extensions’ are included to make sure smoother operations of a browser (extensions, which interfere with the webpages particularly can disrupt the automation procedure).
Running the shorter code block will open your browser.
When the browser gets opened, we would require to automate the item search. The Selenium tool helps you find HTML elements with different techniques including the class, id, CSS selectors, as well as XPath that is the XML path appearance.
Then how do you recognize which features to get? An easy way of doing this is using Chrome’s inspect tool:
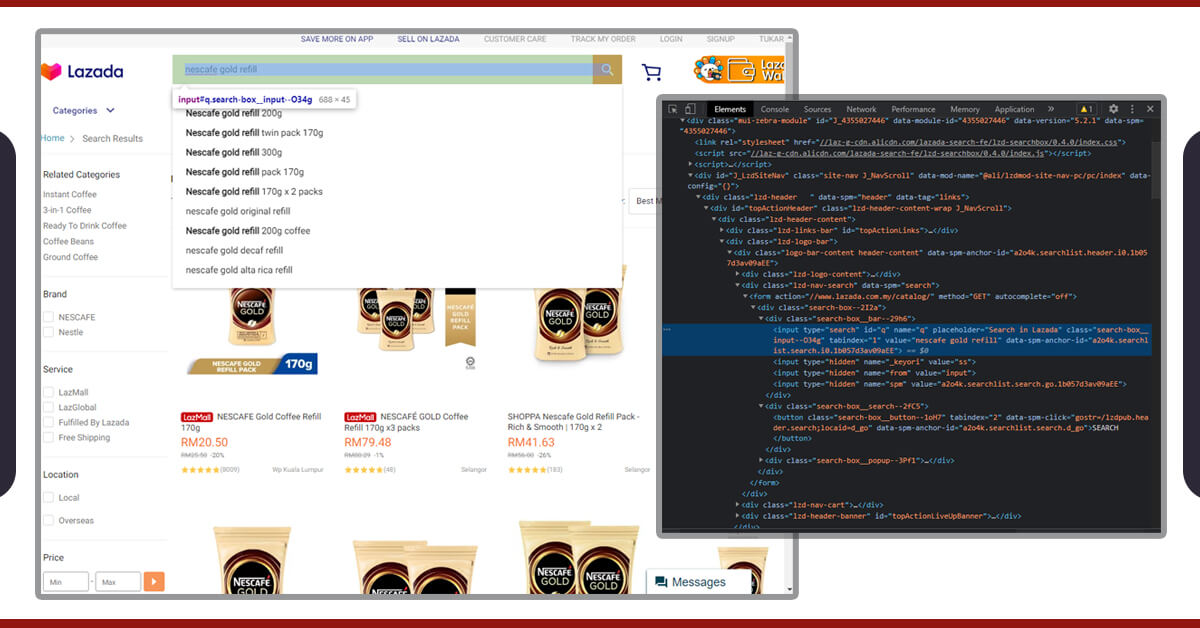
search_bar = browser.find_element_by_id('q')
search_bar.send_keys(search_item).submit()
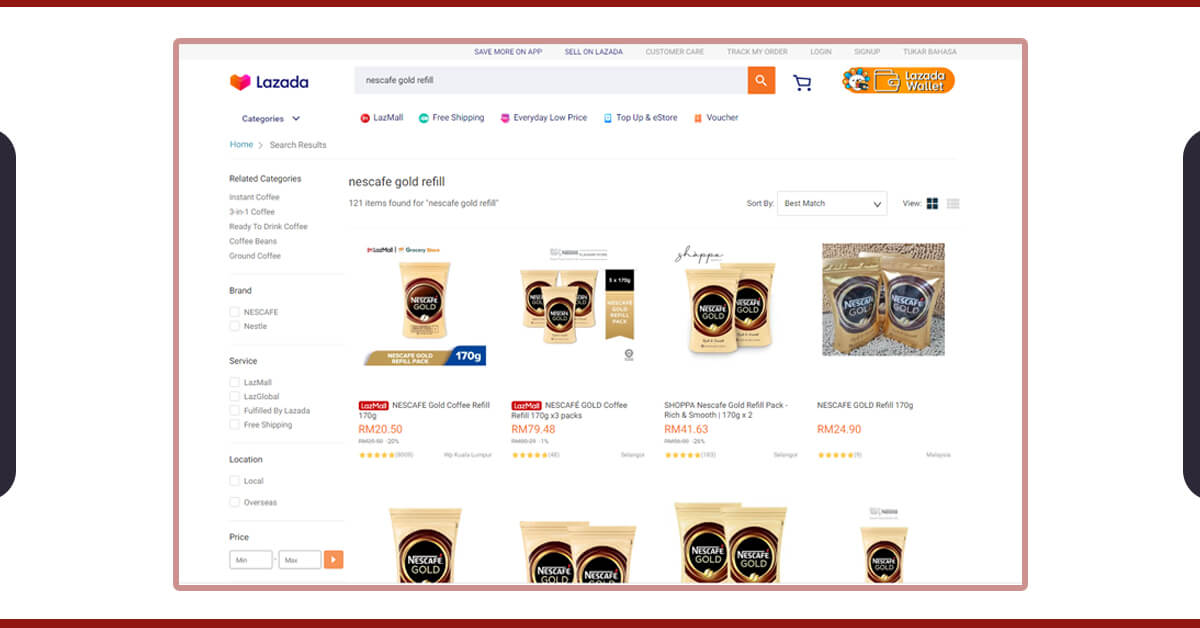
That was the easy part. Now a part comes that could be challenging even more in case, you try extract data from Shopee website!
For working out about how you might scrape item names as well as pricing from Lazada, just think about how you might do that manually. What you can? Let’s see:
- Copy all the item names as well as their prices onto the spreadsheet table;
- Then go to next page as well as repeat the initial step till you’ve got the last page
That’s how we will do that in the automation procedure! To perform that, we will have to get the elements having item names as well as prices with the next page’s button.
With the Chrome’s inspect tool, it’s easy to see that product titles with prices have class names called ‘c16H9d’ as well as ‘c13VH6’ respectively. So, it’s vital to check that the similar class of names applied to all items on a page to make sure successful extraction of all items on a page.
item_titles = browser.find_elements_by_class_name('c16H9d')
item_prices = browser.find_elements_by_class_name('c13VH6')
After that, we have unpacked variables like item_titles as well as item_prices in the lists:
# Initialize empty lists
titles_list = []
prices_list = []
# Loop over the item_titles and item_prices
for title in item_titles:
titles_list.append(title.text)
for price in item_prices:
prices_list.append(prices.text)
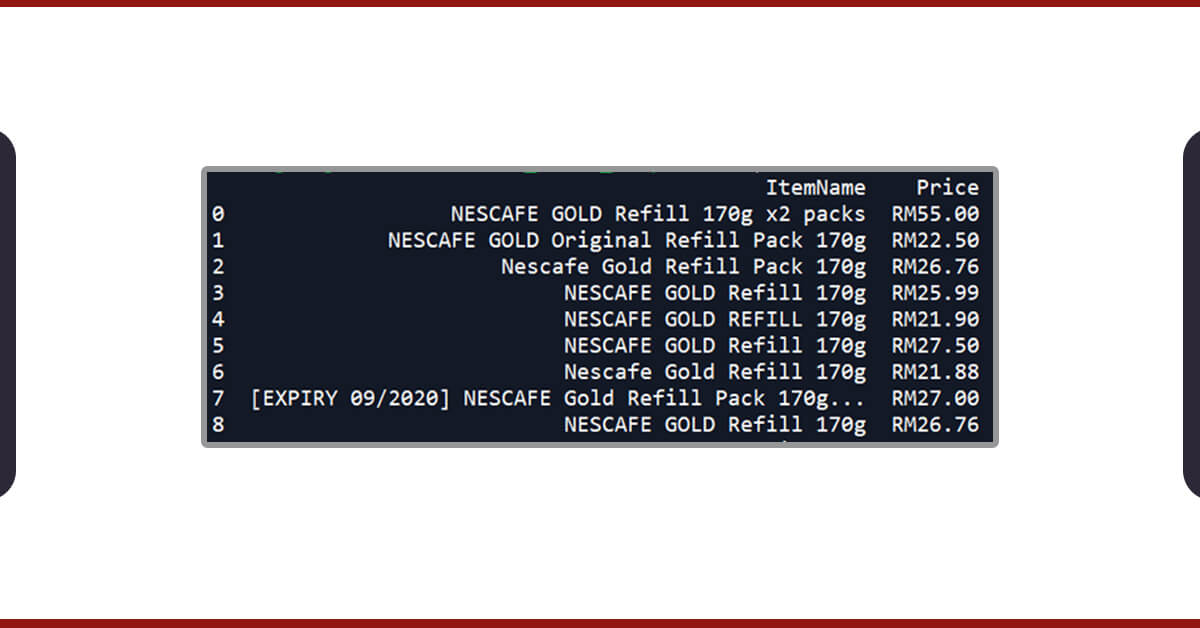
When we print both the lists, it will show the following outputs:
[‘NESCAFE GOLD Refill 170g x2 packs’, ‘NESCAFE GOLD Original Refill Pack 170g’, ‘Nescafe Gold Refill Pack 170g’, ‘NESCAFE GOLD Refill 170g’, ‘NESCAFE GOLD REFILL 170g’, ‘NESCAFE GOLD Refill 170g’, ‘Nescafe Gold Refill 170g’, ‘[EXPIRY 09/2020] NESCAFE Gold Refill Pack 170g x 2 — NEW PACKAGING!’, ‘NESCAFE GOLD Refill 170g’] [‘RM55.00’, ‘RM22.50’, ‘RM26.76’, ‘RM25.99’, ‘RM21.90’, ‘RM27.50’, ‘RM21.88’, ‘RM27.00’, ‘RM26.76’, ‘RM23.00’, ‘RM46.50’, ‘RM57.30’, ‘RM28.88’]
When we complete scraping from the page, it’s time to move towards the next page. Also, we will utilize a find_element technique using XPath. The use of XPath is very important here as next page buttons have two classes, as well as a find_element_by_class_name technique only gets elements from the single class.
It’ very important that we require to instruct the browser about what to do in case, the subsequent page button gets disabled (means in case, the results are revealed only at one page or in case, we’ve got to the end page results.
try:
browser.find_element_by_xpath(‘//*[@class=”ant-pagination-next” and not(@aria-disabled)]’).click()
except NoSuchElementException:
browser.quit()
So, here, we’ve commanded the browser for closing in case the button gets disabled. In case, it’s not got disabled, then the browser will proceed towards the next page as well as we will have to repeat our scraping procedure.
Luckily, the item that we have searched for is having merely 9 items that are displayed on a single page. Therefore, our scraping procedure ends here!
Now, we will start to analyze data that we’ve extracted using Pandas. So, we will start by changing any two lists to the dataframe:
dfL = pd.DataFrame(zip(titles_list, prices_list), columns=[‘ItemName’, ‘Price’])
If the printing of dataframe is done then it shows that our scraping exercise is successful!
When the datasets look good, they aren’t very clean. In case, you print information of a dataframe through Pandas .info() technique it indicates that a Price column category is the string object, instead of the float type. It is very much expected because every entry in a Price column has a currency symbol called ‘RM’ or Malaysian Ringgit. Though, in case the Pricing column is not the float or integer type column, then we won’t be able to scrape any statistical characteristics on that.
`Therefore, we will require to remove that currency symbol as well as convert the whole column into the float type using the following technique:
dfL[‘Price’] = dfL[‘Price’].str.replace(‘RM’, ‘’).astype(float)
Amazing! Although, we need to do some additional cleaning. You could have observed any difference in the datasets. Amongst the items, which is actually the twin pack that we would require to remove from the datasets.
Data cleaning is important for all sorts of data analysis as well as here we would remove entries, which we don’t require with the following code:
# This removes any entry with 'x2' in its title dfL = dfL[dfL[‘ItemName’].str.contains(‘x2’) == False]
Looking to scrape eCommerce websites?
Get a Quote!
Though not required here, you can also make sure that different items, which seem are the items that we precisely searched for. At times other associated products might appear in the search lists, particularly if the search terms aren’t precise enough.
For instance, if we would have searched ‘nescafe gold refill’ rather than ‘nescafe gold refill 170g’, then 117 items might have appeared rather than only 9 that we had scraped earlier. These extra items aren’t some refill packs that we were looking for however, rather capsule filtering cups instead.
Nevertheless, this won’t hurt for filtering your datasets again within the search terms:
dfL = dfL[dfL[‘ItemName’].str.contains(‘170g’) == True]
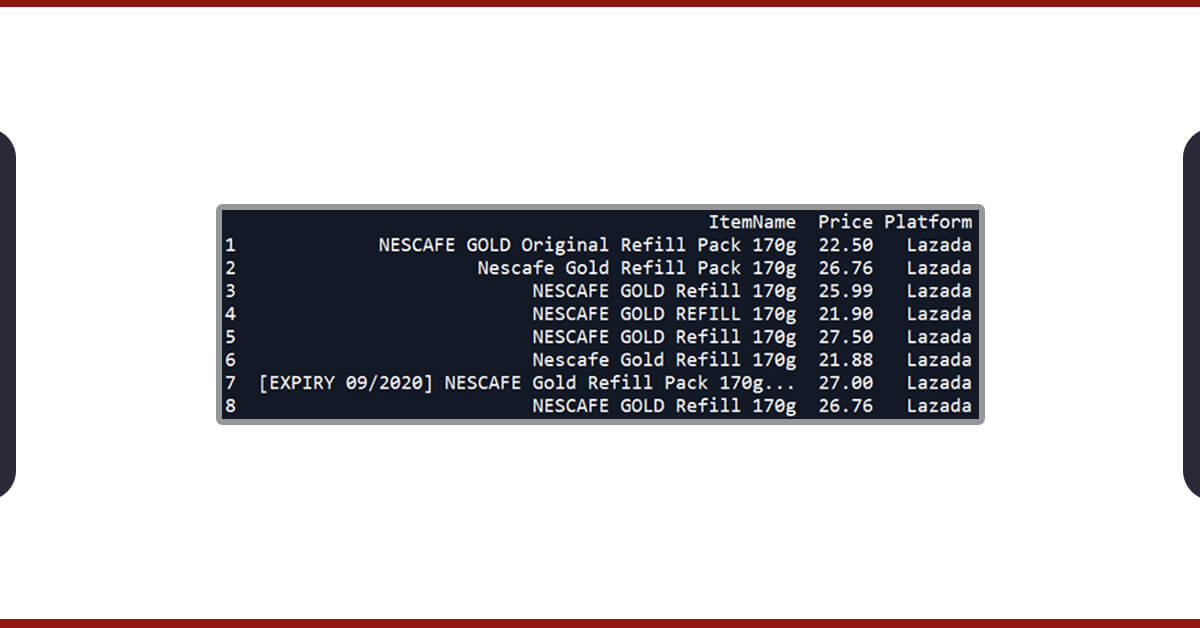
In the final game, we would also make a column called ‘Platform’ as well as allocate ‘Lazada’ to all the entries here. It is completed so that we could later group different entries by these platforms (Shopee and Lazada) whenever we later organize the pricing comparison between two platforms.
dfL[‘Platform’] = ‘Lazada’
Hurrah! Finally, our dataset is ready and clean!
Now, you need to visualize data with Seaborn and Matplotlib. We would be utilizing the box plot because it exclusively represents the following main statistical features (recognized as a five number summary) in this chart:
Highest Pricing
Lowest Pricing
Median Pricing
25th as well as 75th percentile pricing
# Plot the chart sns.set() _ = sns.boxplot(x=’Platform’, y=’Price’, data=dfL) _ = plt.title(‘Comparison of Nescafe Gold Refill 170g prices between e-commerce platforms in Malaysia’) _ = plt.ylabel(‘Price (RM)’) _ = plt.xlabel(‘E-commerce Platform’) # Show the plot plt.show()
Every box represents the Platform as well as y-axis shows a price range. At this time, we would only get one box, because we haven’t scraped and analyzed any data from a Shopee website.
We could see that item prices range among RM21–28, having the median pricing between RM27–28. Also, we can see that a box has shorter ‘whiskers’, specifying that the pricing is relatively constant without any important outliers. To know more about understanding box plots, just go through this great summary!
That’s it now for this Lazada website! During Part 2, we will go through the particular challenges while extracting the Shopee website as well as we would plot one more box plot used for Shopee pricing to complete the comparison!
Looking to scrape price data from e-commerce websites? Contact Retailgators for eCommerce Data Scraping Services.




Leave a Reply
Your email address will not be published. Required fields are marked