
Web scrapers are tools commonly used to get information from websites. Building one requires programming skills, but it's not as complicated as you think. The success of using a web scraper for eCommerce data gathering depends on more than just the scraper itself. Things like the website you're targeting and the anti-bot measures it uses also matter.
If you want to use a web scraper to collect data or track prices over time, you must keep it updated and manage it well.
What Do You Mean by Web Scraping in the E-commerce Industry?
Web scraping in the e-commerce industry is the automated process of extracting data from online store websites related to the retail industry. This data can cover product details, pricing details, customer feedback, the number of items in stock, and any other data businesses find essential to their work. Web scraping in e-commerce allows businesses to collect diverse data on their competitors and discover trends. It also helps to create optimal pricing strategies, organize orders in the product catalog, and make better choices on all fronts. Through the implementation of web scraping strategies, online retailers have the chance to obtain valuable data on their target market and the industry in which they work. This, in turn, can benefit a company in terms of its driving force for remaining competitive and making informed business decisions.
What is Web Scraping Used For?
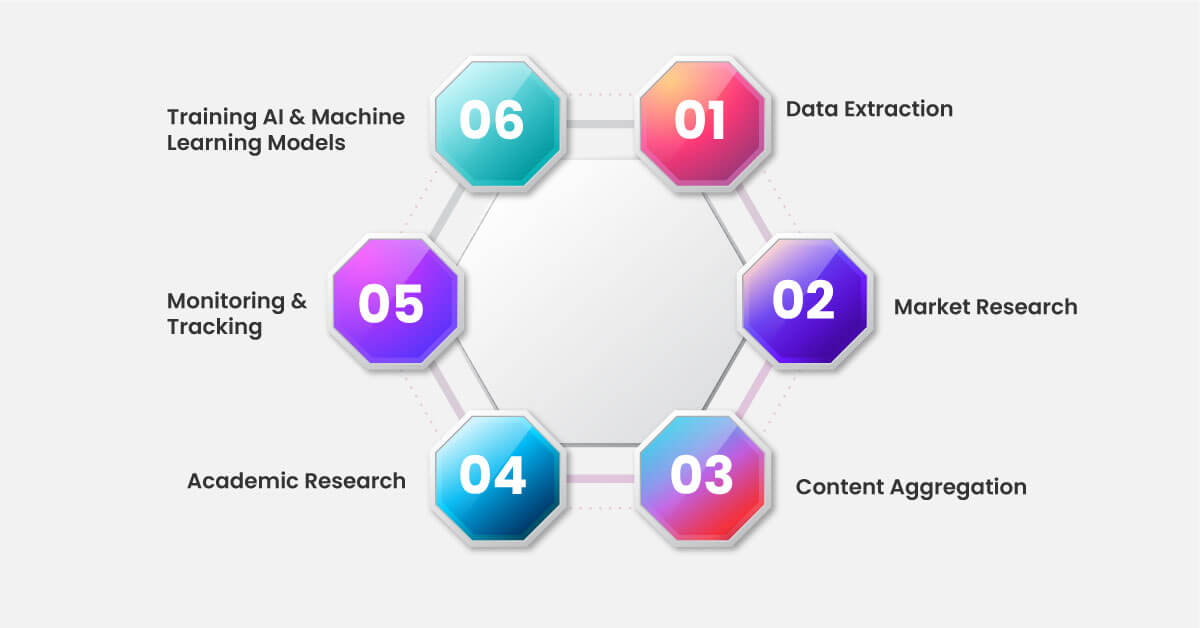
Web scraping is the most convenient procedure for extracting data from web pages using specific tools or scripting languages. Let's take a closer look at how it works and why it's so beneficial:
Data Extraction
Scraping websites increases the process of data appropriation from sites whose data is not easy to obtain. The data could contain a variety of things, such as product descriptions and prices, reviews, press releases, weather updates, and even stock updates.
Market Research
Businesses employ web scraping technology to stay ahead of the competition and be aware of market movements. This, in essence, allows them to gain insight into the market by collecting information such as competitor pricing, customer reviews, and market trends. This provides them with grounds to make proper choices for their own production and sales.
Content Aggregation
In the same way that web scraping brings in data from different sources into one location, you will find this funnel packed with movie and book reviews. Websites focused on aggregation that use web scraping to collect data from different sources and then present the information in one convenient location.
Lead Generation: The last web scraping function is to obtain potential customers. In this connection, the process of getting people's email addresses or phone numbers from websites means creating a database to use in sales and marketing actions.
Academic Research
Researchers focus on web scraping to collect data for their articles, which mainly include social media evaluation, sentiment analysis, and opinion mining. Hence, they can access any place faster than before, using it for data processing and spotting patterns and trends.
Monitoring and Tracking
Screening is a technology that monitors changes on a web page, such as price or product availability updates. This information is an important tool for price comparison, stock visibility, and competitor activities.
Training AI and Machine Learning Models
Web scraping yields datasets useful for AI or machine learning model training. Gathering data from diverse sources makes it possible to build sizable datasets for applications like image recognition, sentiment analysis, and text categorization.
What are the Requirements for Building A Web Scraper?
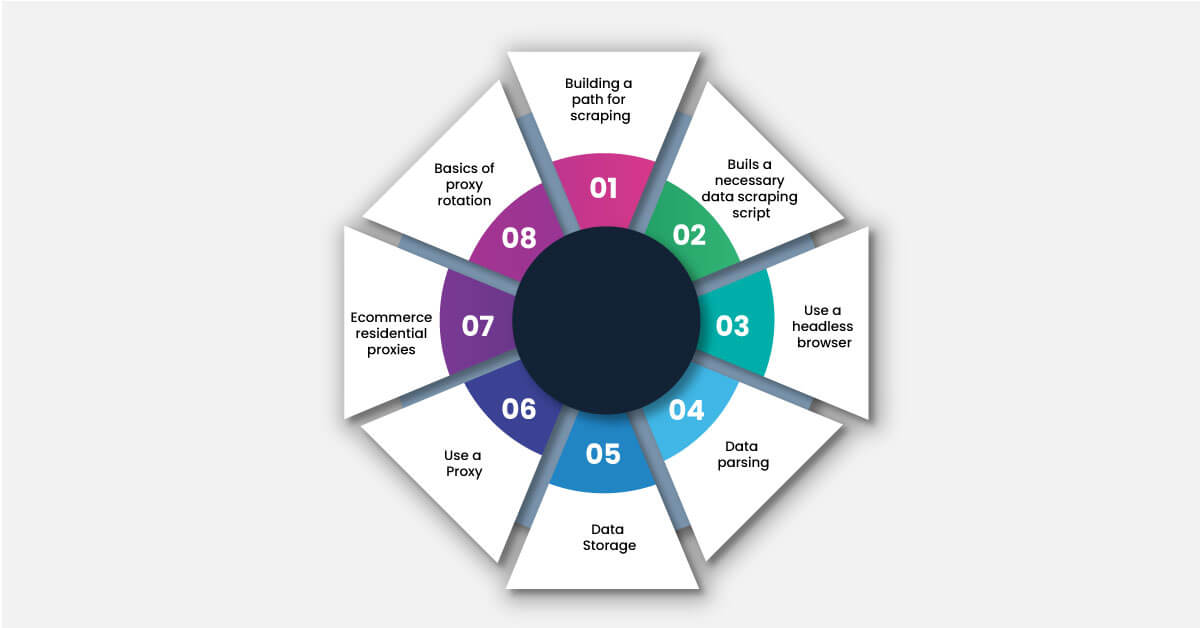
When developing a basic web scraper, it is important to consider a few aspects that ensure a smooth data extraction process. We have compiled prerequisites to build a web scraper for diverse requirements:
Building a Path for Scraping
Creating a path for scraping is a crucial step in nearly every data scraping technique. It involves compiling a list of different URLs extracted from diverse datsets. While gathering a handful of URLs can seem clear, building a path for scraping demands careful attention and effort.
Sometimes, constructing a path to perform the data scraping requires additional steps. For instance, scraping the initial page is important to collect the necessary URLs. Consider the process of creating a path for scraping specific products on an ecommerce business website:
- Extract the search result page.
- Extract URLs of product page .
- Scrape latest URLs.
- Parse the data based on specific criteria.
Thus, constructing a path to perform the data scraping is more than just gathering a bunch of readily available URLs. Creating an automated and advanced process make sure that no crucial URLs are overlooked. All subsequent scraping and data analysis efforts rely on the data obtained from the URLs highlighted in the path to perform the data scraping process. Creating a scraping path necessitates understanding the industry and specific competitors. The data acquisition process can commence only when URLs are gathered methodically and strategically.
Build the Necessary Data Scraping Scripts
Creating a web scraping script requires a good understanding of programming. While Python is commonly used for basic data extraction and gathering scripts due to its wealth of useful libraries, it's not the only option available.
The process of developing a web scraping script involves several stages:
- Determine the data type to be scraped, such as pricing and product details.
- Identify the location of the data and how it's structured.
- Install and import necessary libraries, like BeautifulSoup for the process of data parsing and CSV or JSON to save output.
- Write the data extraction script.
The initial step is usually straightforward, but the real work begins in step two.
Various types of product data are often displayed in various ways on websites.
Ideally, data from various URLs in your scraping path would be organized uniformly, simplifying extraction. In such cases, traditional data extraction methods using Python libraries like BeautifulSoup or LXML would not be enough. To scrape such elements, a headless browser is required alongside other tools.
Use a Headless Browser
The Headless browsers are considered the primary tools for scraping data from JavaScript elements. Web drivers offer an alternative solution, as many popular browsers support them. However, web drivers tend to be slower compared to headless browsers because they operate similarly to web browsers used in daily routines. Using both methods may yield slightly different results. Testing both approaches for every project is advisable to determine which suits the requirements better.
Chrome holds 68.60% of the market share, while Firefox accounts for 8.17%. Both browsers offer headless modes, expanding the range of available options.
Additionally, Zombie.JS and PhantomJS are the most popular options among different web scrapers available for headless browsing. It's important to note that headless browsers require automation techniques and tools to execute data scraping scripts, with Selenium being a widely-used framework for this purpose.
Data Parsing
It is the crucial step of converting the collected data into an understandable and useful format. Many data collection methods provide outputs that are difficult for humans to comprehend, so parsing and organizing the data into a structured format is essential. Python is widely favored for acquiring pricing intelligence because of its accessible and well-optimized libraries. Popular choices for data parsing include LXML,Beautiful Soup, and several others.
Parsing enables developers to sift through data by locating specific sections within XML or HTML files. Tools like Beautiful Soup offer built-in commands and functionalities to simplify the parsing process. These parsing libraries typically streamline the navigation through extensive data sets by associating print or search commands with common XML/HTML document elements.
Data Storage
Storing data involves considering both its type and volume. Creating a dedicated and suitable database is advisable for continuous projects like pricing intelligence. However, storing data in a few JSON or CSV files can suffice for shorter or one-time projects. The data storage is generally straightforward, but cleanliness is crucial. Retrieving data from improperly indexed databases can become a big hurdle in no time.
Once you've collected and organized your data, the next step is to store it for the long term. This is the concluding part of the process. Writing down the steps to get the data, figuring out what you're looking for, and putting everything in order are clear tasks. But the tricky part is making sure your actions don't look like those of a robot to the website you're getting the data from. You also need to make sure your IP address doesn't get blocked, which is the core challenge.
Use a Proxy
The steps mentioned above may seem concise, including creating the scraping script, selecting appropriate libraries, and exporting data into JSON or CSV files.
Since the scripts for data extraction operate similarly to bots by accessing URLs in a scraping path, they can inadvertently lead to IP bans. To mitigate the risk of being banned and ensure uninterrupted scraping, proxies are employed.
Using proxies, however, doesn't guarantee immunity from IP bans, as websites may also detect proxy usage. Premium proxies with advanced features that make them difficult to detect are preferred to bypass website restrictions effectively.
Additionally, implementing IP rotation can help prevent bans. However, scraping challenges persist due to sophisticated anti-bot measures that eCommerce sites and search engines employ. IP rotation and emulation of human behavior are crucial to data gathering success.
E-commerce Residential Proxies
Residential proxies play a crucial role in e-commerce data collection methods because many of these methods require maintaining a consistent identity. E-commerce companies often employ various algorithms to adjust prices based on consumer attributes. Residential proxies serve as the primary defense for e-commerce data-gathering tools. As websites deploy modern anti-scraping measures and detect automated bot-like behavior, these proxies enable web scrapers to evade suspicion.
Effective strategies must be employed to utilize residential proxies efficiently. Residential proxies are commonly used in data extraction as they allow users to bypass geo-blocks and access restricted sites. These proxies are tied to physical addresses, maintaining a semblance of normal identity and reducing the likelihood of being banned.
Basics of Proxy Rotation
Understanding proxy rotation and how to avoid getting blocked by websites requires practice which takes time. Every website has its own rules for what looks like automated activity, so you have to adjust your approach accordingly.
Here are some simple steps for using proxies in e-commerce data collection activities:
- Stick with the default session out times, which are usually around 10 minutes.
- If a website gets a lot of traffic or if its pages are huge, consider making your sessions last longer.
- You don't need to create your proxy rotation system from scratch. Tools like Proxifier or FoxyProxy can help with basic tasks.
- When you're scraping data from a website, try to act like a normal person browsing the site.
- Start by spending some time on the homepage, then visit a few product pages. This makes your activity look more natural.
Conclusion
Extracting data is crucial for business growth as it guides decision-making. While basic web scraping seems simple, the real challenge arises when you try to retrieve the data. Many websites have robust anti-bot measures that detect and block bot activity. It's best to use a premium proxy to increase your chances of success.
Retailgators offers dedicated IP addresses specifically for web scraping, ensuring fast speeds and full control over your IP's behavior. You can further enhance your success rates by using your IPs alongside a reliable proxy rotator. IP rotation has been shown to reduce the risk of your IP being banned by websites, giving you a better shot at obtaining the data you need.




Leave a Reply
Your email address will not be published. Required fields are marked