
Introduction
In a web extracting blog, we can construct an Amazon Scraper Review with Python using 3 steps that can scrape data from different Amazon products like – Content review, Title Reviews, Name of Product, Author, Product Ratings, and more, Date into a spreadsheet. We develop a simple and robust Amazon product review scraper with Python.
Here we will show you 3 steps about how to extract Amazon review using Python
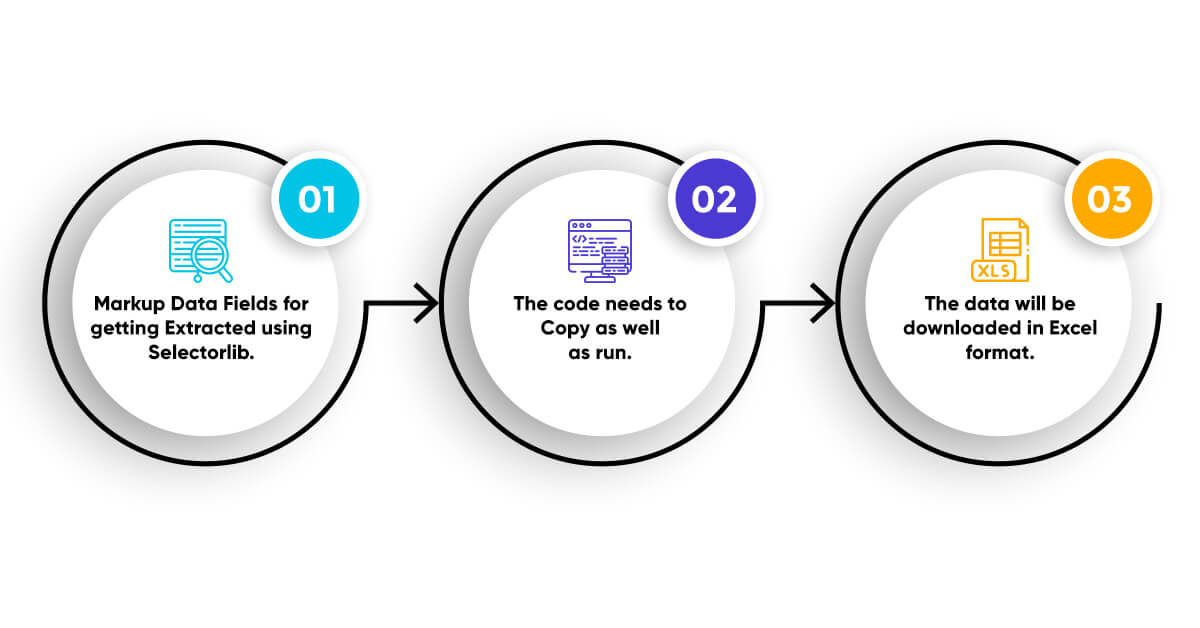
- 1. Markup Data Fields for getting Extracted using Selectorlib.
- 2. The code needs to Copy as well as run.
- 3. The data will be downloaded in Excel format.
We can let you know how can you extract product information from the Amazon result pages, how can you avoid being congested by Amazon, as well as how to extract Amazon in the huge scale.
Here, we will show you some data fields from Amazon we scrape into the spreadsheets from Amazon:
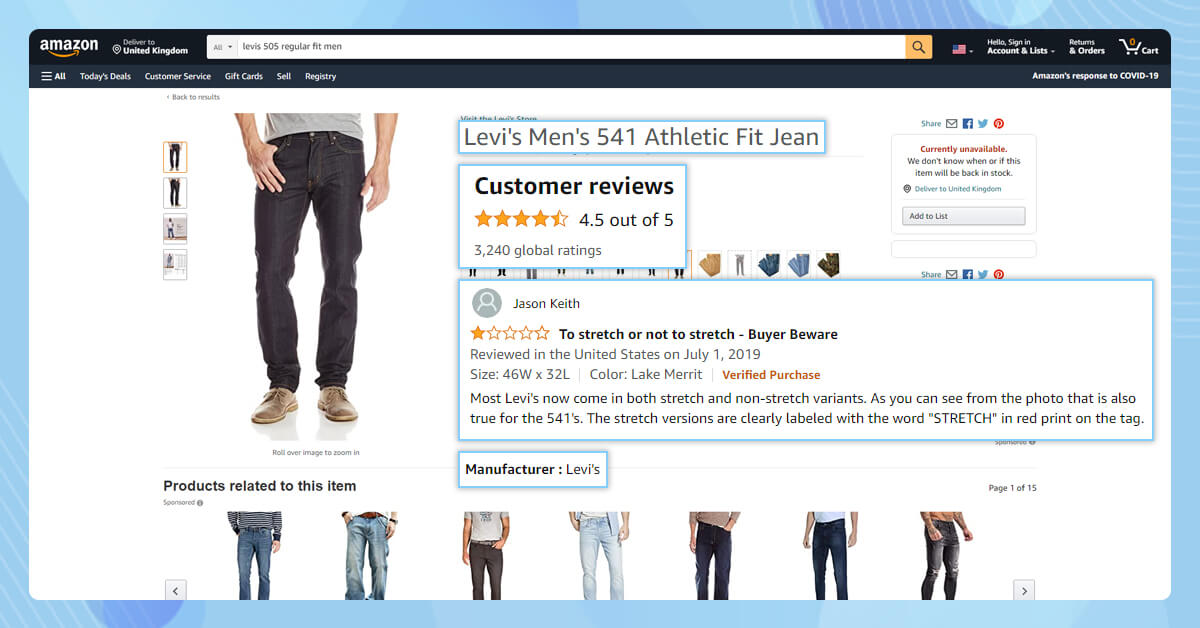
- Name of Product
- Review title
- Content Review or Text Review
- Product Ratings
- Review Publishing Date
- Verified Purchase
- Name of Author
- Product URL
We help you save all the data into Excel Spreadsheet.
Install required package for Amazon Website Scraper Review
Web Extracting blog to extract Amazon product review utilizing Python 3 as well as libraries. We do not use Scrapy for a particular blog. This code needs to run quickly, and easily on a computer.
If python 3 is not installed, you may install Python on Windows PC.
We can use all these libraries: -
- Request Python, you can make download and request HTML content for different pages using (http://docs.python-requests.org/en/master/user/install/)
- Use LXML to parse HTML Trees Structure with Xpaths – (http://lxml.de/installation.html)
- Dateutil Python, for analyzing review date (https://retailgators/dateutil/dateutil/)
- Scrape data using YAML files to generate from pages that we download.
Installing them with pip3
pip3 install python-dateutillxml requests selectorlib
The Code
Let us generate a file name reviews.py as well as paste the behind Python code in it.
What Amazon Review Product scraper does?
- 1. Read Product Reviews Page URL from the file named urls.txt.
- 2. You can use the YAML file to classifies the data of the Amazon pages as well as save in it a file named selectors.yml
- 3. Extracts Data
- 4. Save Data as the CSV known as data.csv filename.
Creating YAML files with selectors.yml
It’s easy to notice the code given which is used in the file named selectors.yml. The file helps to make this tutorial easy to follow and generate.
Selectorlib is the tool, which selects to markup and scrapes data from the web pages easily and visually. The Web Scraping Chrome Extension makes data you require to scrape and generates XPaths Selector or CSS needed to scrape data.
Here we will show how we have marked up field for data we require to Extract Amazon review from the given Review Product Page using Chrome Extension.
When you generate the template you need to click on the ‘Highlight’ option to highlight as well as you can see a preview of all your selectors.
Here we will show you how our templates look like this: -
Running Amazon Reviews Scrapers
You just need to add URLs to extract the text file named urls.txt within the same the folder as well as run scraper consuming the same commend.
This file shows that if we want to search distinctly for earplugs and headphones.
Now, we will show a sample URL - https://www.amazon.com/HP-Business-Dual-core-Bluetooth-Legendary/product-reviews/B07VMDCLXV/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews
It’s easy to get the URL through clicking on the option “See all the reviews” nearby the lowermost product page.
What Could You Do By Scraping Amazon?
The data you collect from the blog can assist you in many ways: -
- 1. You can review information unavailable using eCommerce Data Scraping Services.
- 2. Monitor Customer Options on a product that you can see by manufacturing through Data Analysis.
- 3. Generate Amazon Database Review for Educational Research &Purposes &.
- 4. Monitor product’s quality retailed by a third-party seller.
Build Free Amazon API Reviews using Python, Selectorlib & Flask
In case, you want to get reviews as the API like Amazon Products Advertising APIs – then you can find this blog very exciting.
If you are looking for the best Amazon Review using Python, then you can call RetailGators for all your queries.




Leave a Reply
Your email address will not be published. Required fields are marked