Extracting information from E-Commerce sites such as Alibaba, Amazon, eBay, help to provide enormous opportunity for competitors, market research, and price comparison firm. Being among the foremost e-commerce companies, Alibaba products catalog is huge and handy to anyone who is looking to extract data. Extracting Alibaba Product Data can be difficult if you are not having accurate resources and team to perform Alibaba Product Data Extracting. Outsourcing Alibaba extracting helps you to fulfill all your requirements with dedicated scraping services.
Installing Python 3 with Pip
We utilize Python 3 in this Blog. To begin, you require a PC using Python 3 as well as PIP.
- Mac: - http://docs.python-guide.org/en/latest/starting/install3/osx/
- Linux: - http://docs.python-guide.org/en/latest/starting/install3/linux/
- Window: - https://www.retailgators.com/how-to-install-python3-in-windows-10/
PackagesInstall
Find out more information by installing here -
https://doc.scrapy.org/en/latest/intro/
Creating Scrapy Projects
Let us create scrapy task using the command given below.
It can help to create Scrapy task with the help of Name of Project (scrapy_alibaba) as folder name. This contains all required files with accurate structure as well as basics with each file.
Creating a Spider
The Scrapy has built a command named genspiderso that you can produce the fundamental spider templet.
Let’s produce our spider
This will help to create a file spider/scrapy_alibaba.py for recent templets for crawling Alibaba.com
This code is shown here:
Searching Keywords from the file
Let us make the CSV file it named keywords.csv.
This file shows that if we want to search distinctly for earplugs and headphones.
It’s time to use CSV Python’s standard module for reading the keyword file.
A Complete Scrapy Spider’s Code
You can see the whole code at - https://contactus/retailgators/alibaba-scraper
A spider called alibaba_crawler will look at
https://contactus/retailgators/alibaba-scraper/blob/master/scrapy_alibaba/spiders/alibaba_crawler.py
https://contactus/retailgators/Let’s run this scraper with
It is because Alibaba’s website has discovered to crawl different URLs array /trade. So, you can easily that by visiting robots.txt file, positioned at https://www.alibaba.com/robots.txt
Export Products data inCSV & JSON using Scrapy
The Scrapy offers in-built JSON & CSV formats for output.
CSV output:
JSON Output:
List of Data Fields
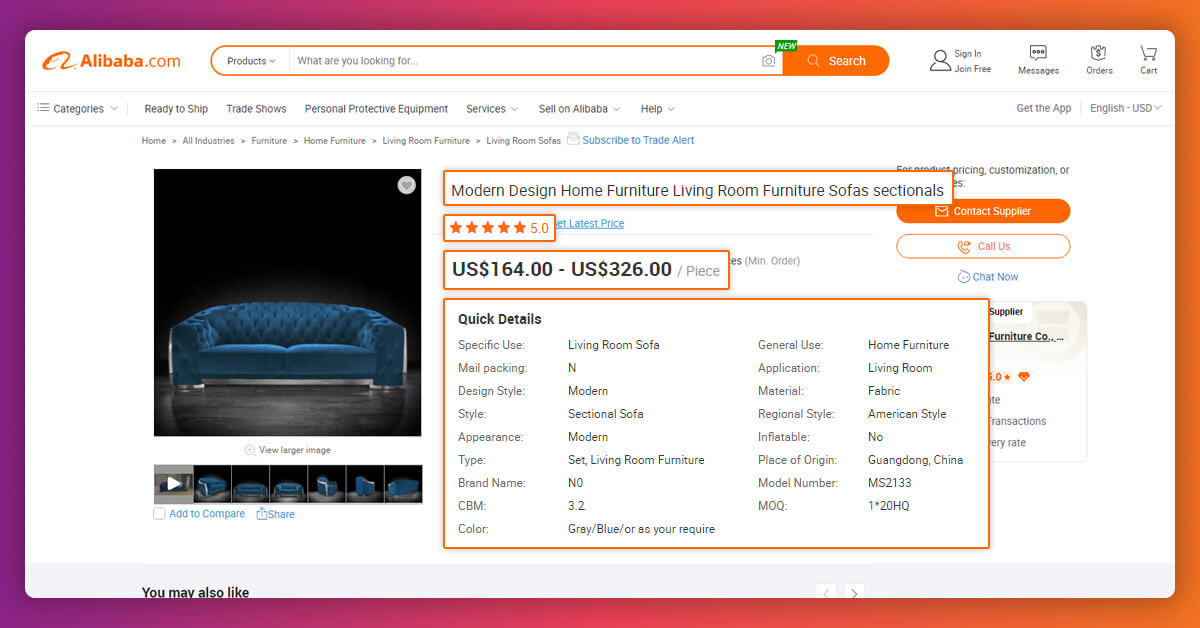
At RetailGators, we extract data for Alibaba Web Data Scraping Services. Data Fields are given below:
- Name of Product
- Product Price Range
- Images of Product
- Product Links
- Minimum Product Order
- Name of Seller
- Seller Reply Rate
- Number of sellers on Alibaba
Key Features of Alibaba Web Scraping Solutions
RetailGators help you to provide fully customized eCommerce Data Scraping that are accessible to deal with data requirements for big companies. Quality and Stability are one of the most important factors if data crawling is concerned. Many DIY Tools are available for scraping through in-house resources.
Here are some of the Key Advantages which is given below: -
- Fully-Customized
- Many Alternative Data Delivery
- Fully manageable Solutions
- High-Quality & Well-Structured Data
What we can scrape from Alibaba?
Website data can help the company to fill the intelligence gap in the association. Here are few things you can do with data scraping from Alibaba.
- Price Comparison Data
- Cataloging Data
- Analyses
Why RetailGators?
If you are looking for the best Alibaba Web Data Scraping Services, then you can contact RetailGators for all your queries.




Leave a Reply
Your email address will not be published. Required fields are marked