
This tutorial blog will help you know how to scrape coupon details from Walmart.
We’ll scrape the following data from every coupon listed in the store:
- Discounted Pricing
- Category
- Brand
- Activation Date
- Expiry Date
- Product Description
- URL
From, below screenshot you can see how data is getting extracted.
You can extract or go further with different coupons created on different brand & filters. But as of now, you need to keep it simple.
Finding the Data
Use any browser or choice a store URL.
https://www.walmart.com/store/5941/washington-dc.
Click the option Coupon on left-hand side and you will able to see list of all the coupons which are offered for Walmart store 5941.
You need to Right-click on the given link on page and select – Inspect Element. The browser will help you to open toolbar and will display HTML Content of the Website, organized nicely. Click on the Network panel so that you can clear all requirements from the Demand table.
Click on this request – ?pid=19521&nid=10&zid=vz89&storezip=20001
You can see this Request URL – https://www.coupons.com/coupons/?pid=19251&nid=10&zid=vz89&storezip=20001
After that, you need to recognize the parameters values- nid, pid, as well as storezip. Check the variables in a page source – https://www.walmart.com/store/5941/washington-dc
Here, you can observe different variables are allocated to the javascript variable _wml.config. You can use variables from different source, page and make the URL of coupons endpoint – https://www.coupons.com/coupons/?pid=19251&nid=10&zid=vz89&storezip=20001
Recover the HTML coupon from URL and you will see how data can be extract from javascript variable APP_COUPONSINC. You can copy data into JSON parser to display data in a structured format.
You can see data fields for the coupons with each coupon ID.
Building the Scraper
Utilize Python 3 in this tutorial. This code is not going to work if you use Python 2.7. You require a computer to start PIP and Python 3 fixed in it.
Many UNIX OS like Mac OS and Linux come with pre-installed Python. However, not each Linux OS ships by default with Python 3.
Let’s check Python version. Exposed the terminal (in Mac OS and Linux) or Facility Prompt (with Windows) and kind
— python version
and click enter. In case, the outputs look like Python 3.x.x, then you need to install Python 3. If you say Python 2.x.x then you are using Python 2. If error comes, that means you don’t have installed Python. If Python 3 is not install then, install that first.
Installing Python 3 as well as Pip
You can go through the guide of installing Python 3 with Linux – http://docs.python-guide.org/en/latest/starting/install3/linux/
The Mac Users may also follow the guide – http://docs.python-guide.org/en/latest/starting/install3/osx/
Installing Packages
- Python requirements, for making requests as well as downloading HTML content about various pages (http://docs.python-requests.org/en/master/user/install/).
- You can use Python LXML to analyze HTML Tree Assembly through Xpaths (Find out how to install it there – http://lxml.de/installation.html)
- UnicodeCSV to handle Unicode typescripts in output folder. Install that using pip install unicodecsv.
The Code
from lxml import html
Perform the code using script name trailed by a store ID:
python3 walmart_coupon_retreiver.py store_id
For example, get the coupon information from store 3305, we can run a script like that:
python3 walmart_coupon_retreiver.py 3305
Also, you will get file name 3305_coupons.csv which will remain in the similar folder as a script. The result file will appearance similar.
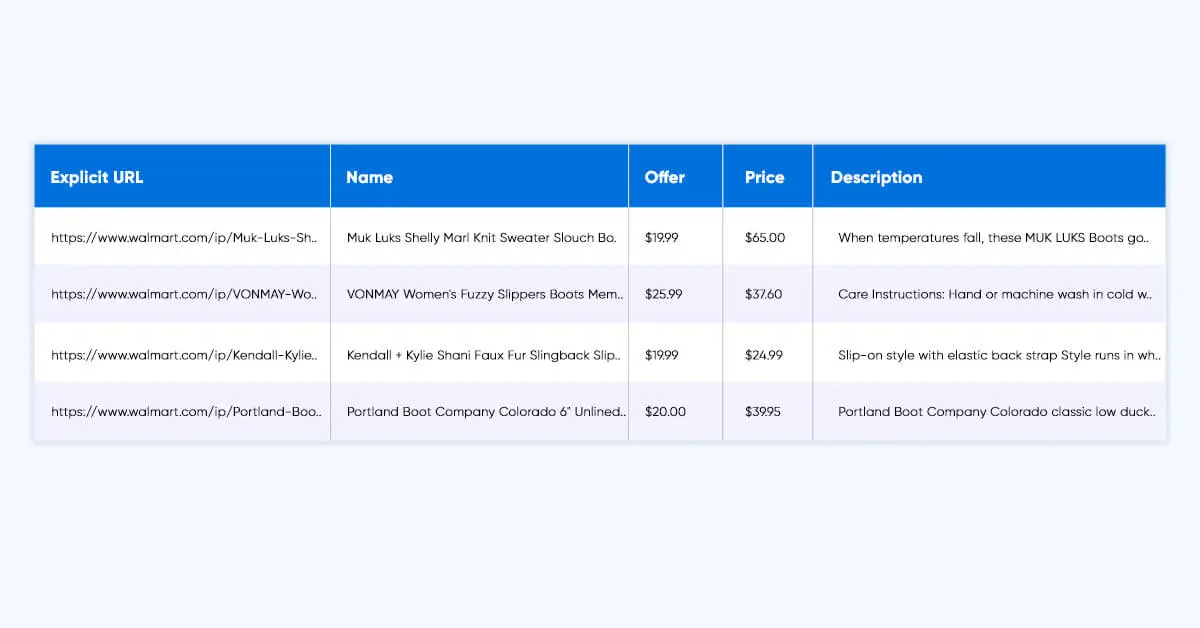
Identified Limitations
The given code works for extract eCommerce Data Scraping coupons information of Walmart stores for store IDs obtainable on Walmart.com. In case, you wish to extract data of millions of pages you need to go through more sources.
If you are looking for the professional with scraping complex website, then you can contact RetailGators for all your queries.






