
In this project, we would try at pagination with Selenium for cycle through pages of the Amazon results pages and save all the data in the .jsonl file format.
What is Selenium?
Selenium is the open-source browsing automation tool, predominantly used to test web applications. It can mimic the user inputs like key presses, mouse movements, as well as page navigation. Also, there are many techniques that allow element selection on a page. The key workhorse after a library is Webdriver that makes browser automation tasks a very easy job to do.
Necessary Package Installation
For the project here, we will require to install Selenium together with some other packages.
Reminder: For this project, we will use a Mac.
For installing Selenium, you just need to type following in the terminal:
pip install selenium
For managing a webdriver, we would utilize a webdriver-manager. You could utilize Selenium for controlling most well-known web browsers like Internet Explorer, Firefox, Chrome, Opera, and Safari. We would be utilizing Chrome.
pip install webdriver-manager
After that, we would also require Selectorlib to download and parse the HTML pages we route to:
pip install selectorlib
Set Up an Environment
After that, make a new folder on the desktop as well as add a few files.
$ cd Desktop $ mkdir amazon_scraper $ cd amazon_scraper/ $ touch amazon_results_scraper.py $ touch search_results_urls.txt $ touch search_results_output.jsonl
You would also require to place the file called “search_results.yml” in a project directory. The file would be utilized later for grabbing data for every product on a page through CSS selectors. You could find a file here.
After that, open the code editor as well as import following in amazon_results_scraper.py file:
from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager from selenium.common.exceptions import NoSuchElementException from selectorlib import Extractor import requests import json import time
Then, make a function named search_amazon, which take a string for items we need to search on Amazon like an input:
def search_amazon(item):
#we will put our code here.
With webdriver-manager, it’s easy to install a right version of ChromeDriver:
def search_amazon(item):
driver = webdriver.Chrome(ChromeDriverManager().install())
Load a Page and Choose Elements
Selenium offers many techniques for choosing page elements. We could choose elements by name, ID, XPath, class name, link text, tag name, as well as CSS Selector. Also, you may use qualified locators for targeting page elements related to other elements. For different objectives, we will utilize ID, XPath, and class name. Let’s load an Amazon homepage. Below the driver element, type these following:
driver.get('https://www.amazon.com')
After that, open Chrome as well as navigate to Amazon homepage, we require to get locations of page elements required to cooperate with. For different objectives, we need to:
- Input name of item(s) that we wish to search into a search bar.
- Then, click on search button.
- Navigate a result page for item(s).
- Repeat through resulting pages.
Then, right click on a search bar as well as from a dropdown menu, you need to click on inspect. It will take you to the section called browser developer tools. After that, click the icon:
Hover on a search bar and click search bar for locating the elements in DOM:
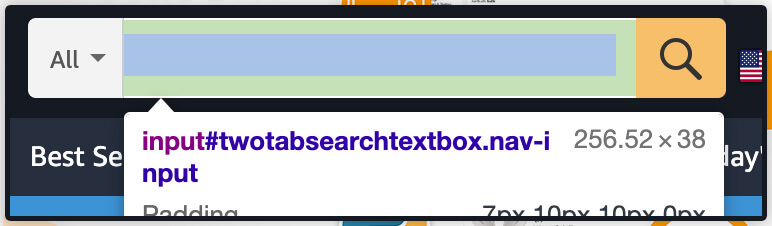
Its search bar is the ‘input’ element having id of “twotabssearchtextbox”. We could interact with the items using Selenium through using find_element_by_id() technique, then send the text input in it through binding .send_keys(‘text that we wish in a search box’) including:
search_box = driver.find_element_by_id('twotabsearchtextbox').send_keys(item)
Then, let’s repeat similar steps we have taken to get a location of a search box with magnifying a glass search button:

For clicking on the items having Selenium, we initially require to choose an item and chain .click() for end of a statement:
search_button = driver.find_element_by_id("nav-search-submit-text").click()
After we click search, we need to wait for a website to load the initial page of the results or we would get errors. You might utilize:
import time time.sleep(5)
However, selenium has an in-built method for telling a driver to wait for any particular amount of time:
driver.implicitly_wait(5)
As the hard part comes, we wish to discover how many result pages we get, as well as repeat through every page. Many elegant ways are there to do that, however, we would utilize a quick solution. We will locate an item on a page, which shows total results and choose it with its XPath.
Here, we can observe that total result pages are shown in a 6th list element (<li> tag) about the list having a class “a-pagination”. Just for fun, we will position two selections within a try or except block: having one for an “a-pagination” tag, as well as if for whatsoever reason which fails, we would choose an element underneath that with a class called “a-last”.
While using Selenium, one common error comes is a NoSuchElementExcemtion that is thrown while Selenium just cannot get a portion on the page. This might happen in case, an element hasn’t loaded or in case, the elements’ position on a page changes. We could catch that error as well as try and choose something else in case, our initial option fails because we utilize a try-except:
try:
num_page = driver.find_element_by_xpath('//*[@class="a-pagination"]/li[6]')
except NoSuchElementException:
num_page = driver.find_element_by_class_name('a-last').click()
Now, it’s time to make the driver wait for some seconds:
driver.implicitly_wait(3)
Plan to get Amazon results data?
Request a Quote!
We have chosen an element on a page, which shows total result pages, as well as we wish to repeat through each page, collecting current URL for the list, which we would later feed into another script. It’s time to use num_page, get text from an element, cast that like an integer, as well as put that into ‘a’ to get a loop:
url_list = []
for i in range(int(num_page.text)):
page_ = i + 1
url_list.append(driver.current_url)
driver.implicitly_wait(4)
click_next = driver.find_element_by_class_name('a-
last').click()
print("Page " + str(page_) + " grabbed")
When we get the links of result pages, tell a driver to leave:
driver.quit()
Recollect a ‘search_results_urls.txt’ file that we had made earlier? We will require to open that from a function within ‘write’ mode and place each URL from an url_list to that on a completely new line:
with open('search_results_urls.txt', 'w') as filehandle:
for result_page in url_list:
filehandle.write('%s\n' % result_page)
print("---DONE---")
This is what we have got so far:
search_button = driver.find_element_by_id("nav-search-submit-text").click()
def search_amazon(item):
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://www.amazon.com')
search_box = driver.find_element_by_id('twotabsearchtextbox').send_keys(item)
search_button = driver.find_element_by_id("nav-search-submit-text").click()
driver.implicitly_wait(5)
try:
num_page = driver.find_element_by_xpath('//*[@class="a-pagination"]/li[6]')
except NoSuchElementException:
num_page = driver.find_element_by_class_name('a-last').click()
driver.implicitly_wait(3)
url_list = []
for i in range(int(num_page.text)):
page_ = i + 1
url_list.append(driver.current_url)
driver.implicitly_wait(4)
click_next = driver.find_element_by_class_name('a-last').click()
print("Page " + str(page_) + " grabbed")
driver.quit()
with open('search_results_urls.txt', 'w') as filehandle:
for result_page in url_list:
filehandle.write('%s\n' % result_page)
print("---DONE---")
Incorporate an Amazon Search Result Pages Scraper in the Script.
As we’ve transcribed our function for searching our items as well as repeat through results pages, we wish to grab as well as save the data. For doing so, we would utilize an Amazon search result page scraper from the retailgators-code.
The extract function would use URL’s in the text file for downloading the HTML, scrape relevant data like pricing, name, as well as product URL. After that, place that into ‘search_results.yml’ files. Underneath the search_amazon() function, position the following:
def scrape(url):
headers = {
'dnt': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'referer': 'https://www.amazon.com/',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
# Download the page using requests
print("Downloading %s"%url)
r = requests.get(url, headers=headers)
# Simple check to check if page was blocked (Usually 503)
if r.status_code > 500:
if "To discuss automated access to Amazon data please contact" in r.text:
print("Page %s was blocked by Amazon. Please try using better proxies\n"%url)
else:
print("Page %s must have been blocked by Amazon as the status code was %d"%(url,r.status_code))
return None
# Pass the HTML of the page and create
return e.extract(r.text)
search_amazon('Macbook Pro') # <------ search query goes here.
After that, call search_amazon() function having name of the item that you wish to search for:
search_amazon('phones')
Finally, we will position a driver code for scrape(url) function afterwards we use search_amazon() function:
# Create an Extractor by reading from the YAML file
e = Extractor.from_yaml_file('search_results.yml')
# product_data = []
with open("search_results_urls.txt",'r') as urllist, open('search_results_output.jsonl','w') as outfile:
for url in urllist.read().splitlines():
data = scrape(url)
if data:
for product in data['products']:
product['search_url'] = url
print("Saving Product: %s"%product['title'].encode('utf8'))
json.dump(product,outfile)
outfile.write("\n")
# sleep(5)
There you are! After running the code, the search_results_output.jsonl file would hold data on all items extracted from the search.
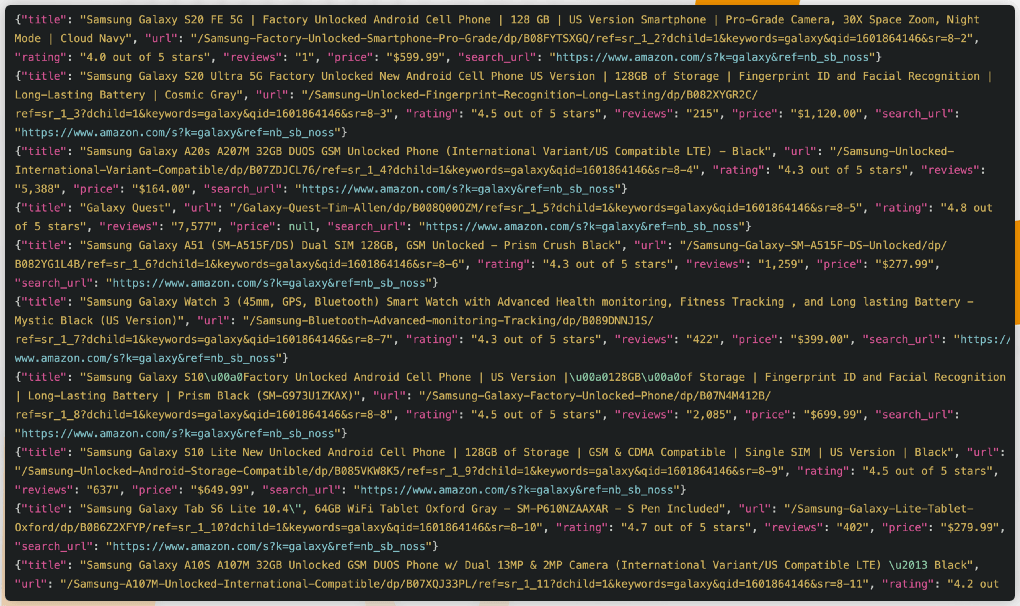
Just go through the completed script:
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import NoSuchElementException
from selectorlib import Extractor
import requests
import json
import time
def search_amazon(item):
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('https://www.amazon.com')
search_box = driver.find_element_by_id('twotabsearchtextbox').send_keys(item)
search_button = driver.find_element_by_id("nav-search-submit-text").click()
driver.implicitly_wait(5)
try:
num_page = driver.find_element_by_xpath('//*[@class="a-pagination"]/li[6]')
except NoSuchElementException:
num_page = driver.find_element_by_class_name('a-last').click()
driver.implicitly_wait(3)
url_list = []
for i in range(int(num_page.text)):
page_ = i + 1
url_list.append(driver.current_url)
driver.implicitly_wait(4)
click_next = driver.find_element_by_class_name('a-last').click()
print("Page " + str(page_) + " grabbed")
driver.quit()
with open('search_results_urls.txt', 'w') as filehandle:
for result_page in url_list:
filehandle.write('%s\n' % result_page)
print("---DONE---")
def scrape(url):
headers = {
'dnt': '1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'sec-fetch-site': 'same-origin',
'sec-fetch-mode': 'navigate',
'sec-fetch-user': '?1',
'sec-fetch-dest': 'document',
'referer': 'https://www.amazon.com/',
'accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',
}
# Download the page using requests
print("Downloading %s"%url)
r = requests.get(url, headers=headers)
# Simple check to check if page was blocked (Usually 503)
if r.status_code > 500:
if "To discuss automated access to Amazon data please contact" in r.text:
print("Page %s was blocked by Amazon. Please try using better proxies\n"%url)
else:
print("Page %s must have been blocked by Amazon as the status code was %d"%(url,r.status_code))
return None
# Pass the HTML of the page and create
return e.extract(r.text)
search_amazon('Macbook Pro') # <------ search query goes here.
# Create an Extractor by reading from the YAML file
e = Extractor.from_yaml_file('search_results.yml')
# product_data = []
with open("search_results_urls.txt",'r') as urllist, open('search_results_output.jsonl','w') as outfile:
for url in urllist.read().splitlines():
data = scrape(url)
if data:
for product in data['products']:
product['search_url'] = url
print("Saving Product: %s"%product['title'].encode('utf8'))
json.dump(product,outfile)
outfile.write("\n")
# sleep(5)
Restrictions
The script works very well on the broad searches, however will fail with more particular searches having items, which return under 5 pages of results. We would work to recover it in future.
Disclaimer
As Amazon won’t like automated extraction of their site as well as you need to always consult.robots file while doing a big-scale data collection. The project was informative and made for learning objectives. Therefore, if you are blocked, you had been warned!
For more information, contact Retailgators or ask for a free quote!




Leave a Reply
Your email address will not be published. Required fields are marked