
The Singapore libraries that are organized by NLB or National Library Board, are wonderful in their accessibilities, physical infrastructure, as well as book selections. You can borrow these library books as they won’t cost you anything and you don’t require to think about storing the library books.
The Singapore libraries are having both a mobile and web app, which permits members to use library accounts as well as other library sources. You can borrow books just by screening the book’s barcode with a smartphone. Screenshots of the NLB mobile app are given below:
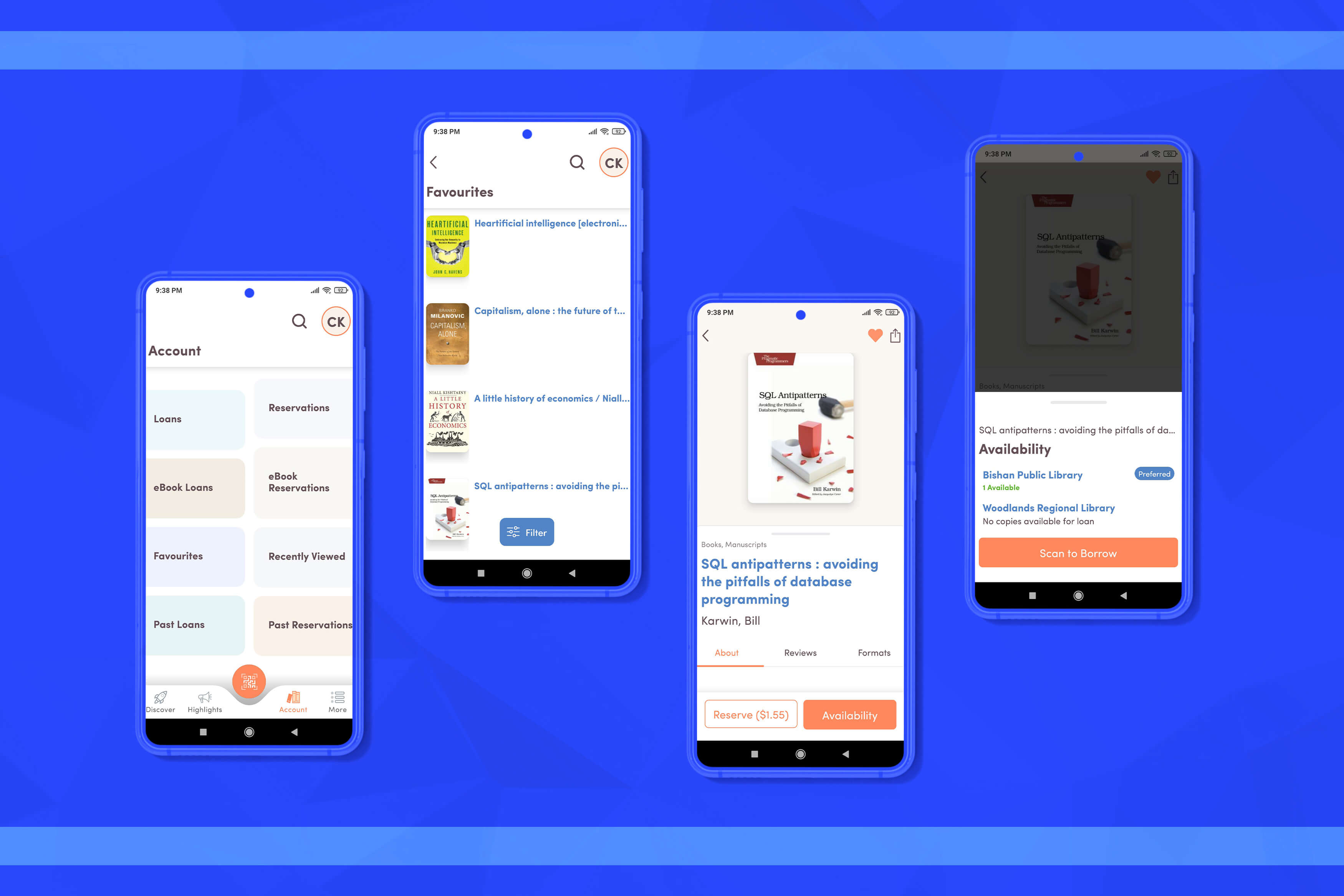
These screenshots don’t have the home page as well as loading time across various touch points before you know if the book is accessible at any particular library or not.
Scraping E-Commerce Product Reviews Data
Web scrapers are not easy to write as well as maintain. So, you can also use web scraping API. While creating a web scraper, you need to know how the data gets represented on a site as well as find out a consistent and logical way of scraping the required data. It doesn’t assist that a few websites don’t get a good and logical structure to do that (some websites do that purposefully to disappoint data scrapers). And as web scrapers rely on a website’s UI, changes in the site’s UI mean you need to take more time to again understand the site’s new UI as well as update your data scraper also.
The Procedure
While creating a Singapore Libraries Scraper, we understood that to get the required data, we need our NLB data scraper to log into the NLB account. To permit our code to work this log, we had to utilize Selenium for our data scraper.
The extraction is done using two Jupyter Notebooks, whereas one scrapes the books, which we have bookmarked whereas the other scrapes books, which we have borrowed.
We have kept data, which we require to log into the NLB account as well as to validate into our Google Sheets in the separate folder, which is not pushed in the Github repo.
For library web scraper, we have decided to utilize Google Sheets as our “frontend”. We also realized that we could use Google Sheets functionalities to calculate different values as well as add color conditions.
Final Result
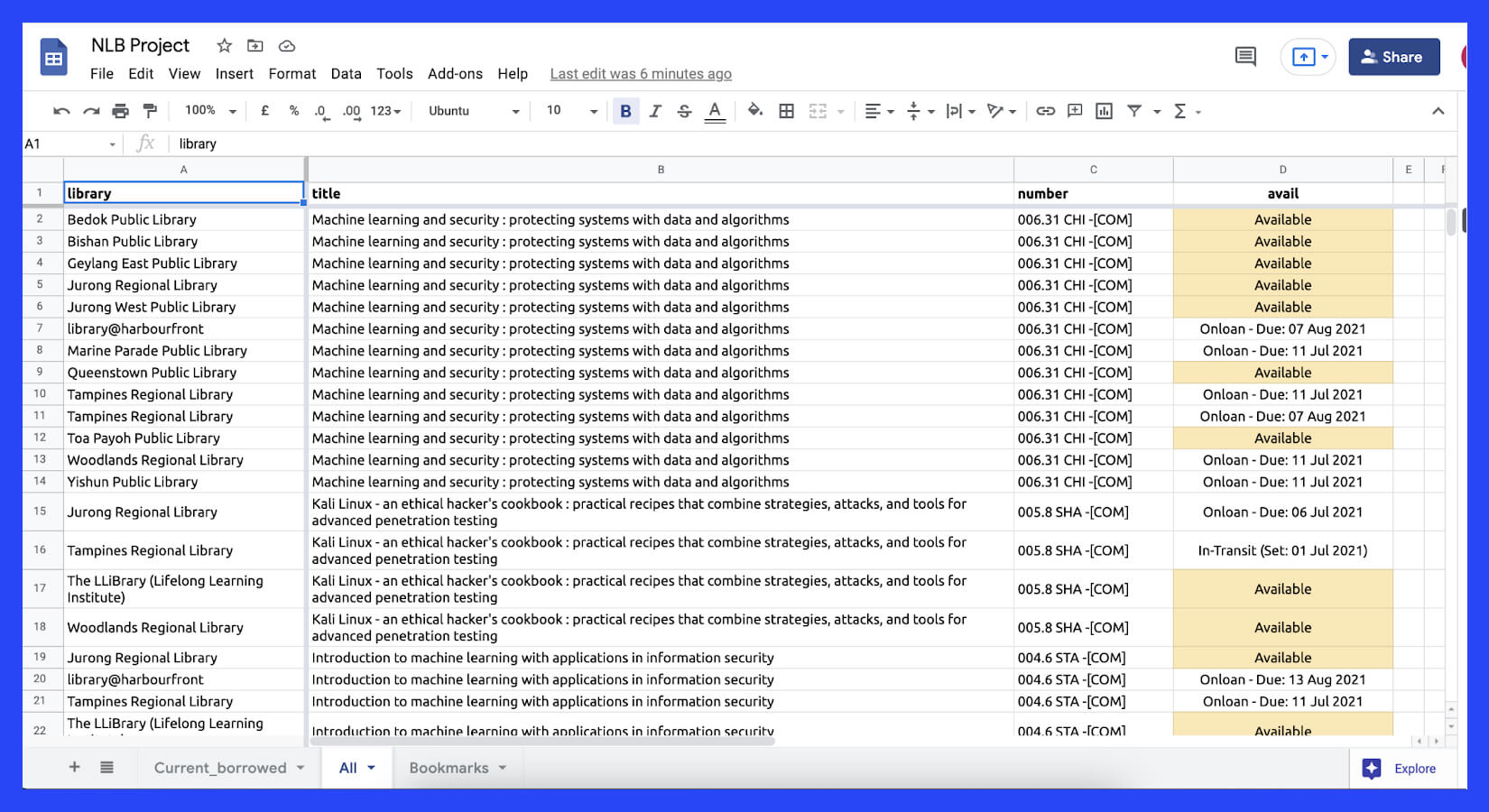
After running this Singapore library web scraper, we will get data of all the books, which we have bookmarked that libraries which are accessible, and in case, books get borrowed, at what time they will be due in our Google sheets.
Google Sheets feel rather heavy on mobile phones, therefore the experience is not so good. Also, there is a time delay between the time when we have last executed our Python data scraper on a laptop as well as when we had done that on a phone.
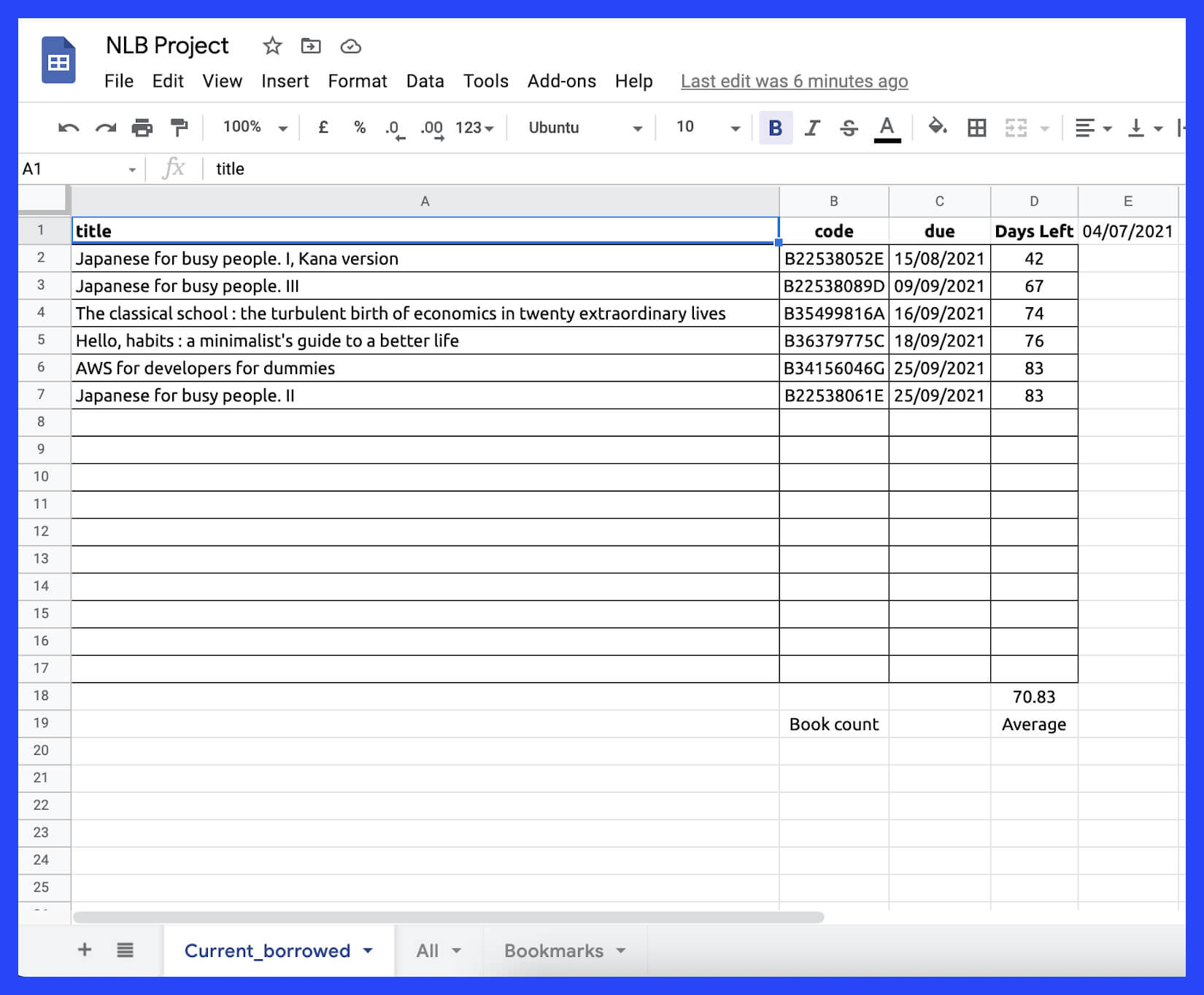
On the smaller and separate script, we can also scrape the books, which we have borrowed, so that we can observe the average and the total number of days left for finishing them all.
Conclusion
Feel free to contact RetailGators in case, you have some recommendations or suggestions! You can also contact us for all your Singapore library data scraping or any other library data scraping services requirements.




Leave a Reply
Your email address will not be published. Required fields are marked