
Introduction
Let’s observe how we may extract Amazon’s Best Sellers Products with Python as well as BeautifulSoup in the easy and sophisticated manner.
The purpose of this blog is to solve real-world problems as well as keep that easy so that you become aware as well as get real-world results rapidly.
So, primarily, we require to ensure that we have installed Python 3 and if not, we need install that before making any progress.
Then, you need to install BeautifulSoup with:
pip3 install beautifulsoup4
We also require soupsieve, library's requests, and LXML for extracting data, break it into XML, and also utilize the CSS selectors as well as install that with:.
pip3 install requests soupsieve lxml
Whenever the installation is complete, open an editor to type in:
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup import requests
After that, go to the listing page of Amazon’s Best Selling Products and review data that we could have.
See how it looks below.
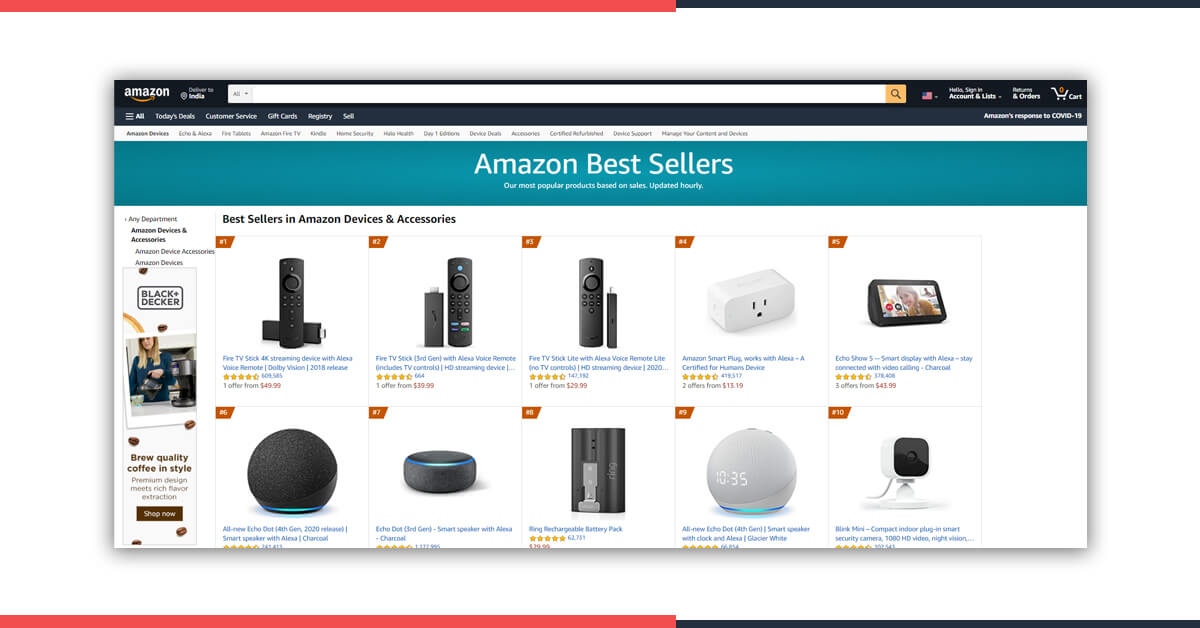
After that, let’s observe the code again. Let’s get data by expecting that we use a browser provided there :
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.amazon.in/gp/bestsellers/garden/ref=zg_bs_nav_0/258-0752277-9771203'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
Now, it’s time to save that as scrapeAmazonBS.py.
If you run it
python3 scrapeAmazonBS.py
You will be able to perceive the entire HTML page.
Now, let’s use CSS selectors to get the necessary data. For doing that, let’s utilize Chrome again as well as open the inspect tool.
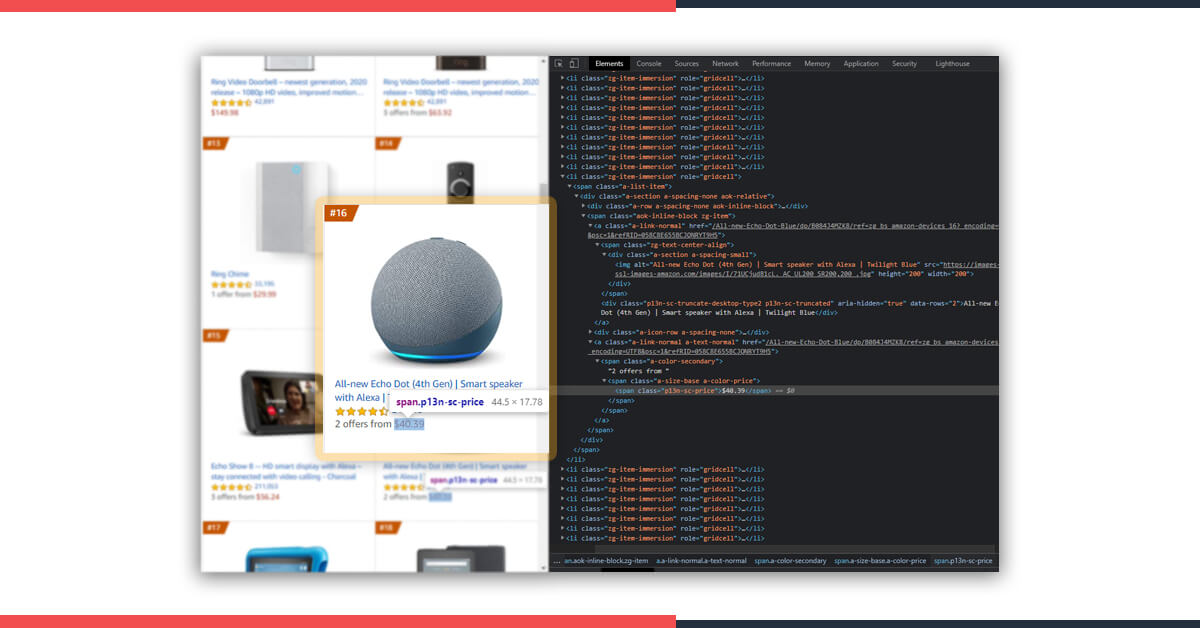
We have observed that all the individual products’ information is provided with the class named ‘zg-item-immersion’. We can scrape it using CSS selector called ‘.zg-item-immersion’ with ease. So, the code would look like :
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.amazon.in/gp/bestsellers/garden/ref=zg_bs_nav_0/258-0752277-9771203'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.zg-item-immersion'):
try:
print('----------------------------------------')
print(item)
except Exception as e:
#raise e
print('')
This would print all the content with all elements that hold products’ information.
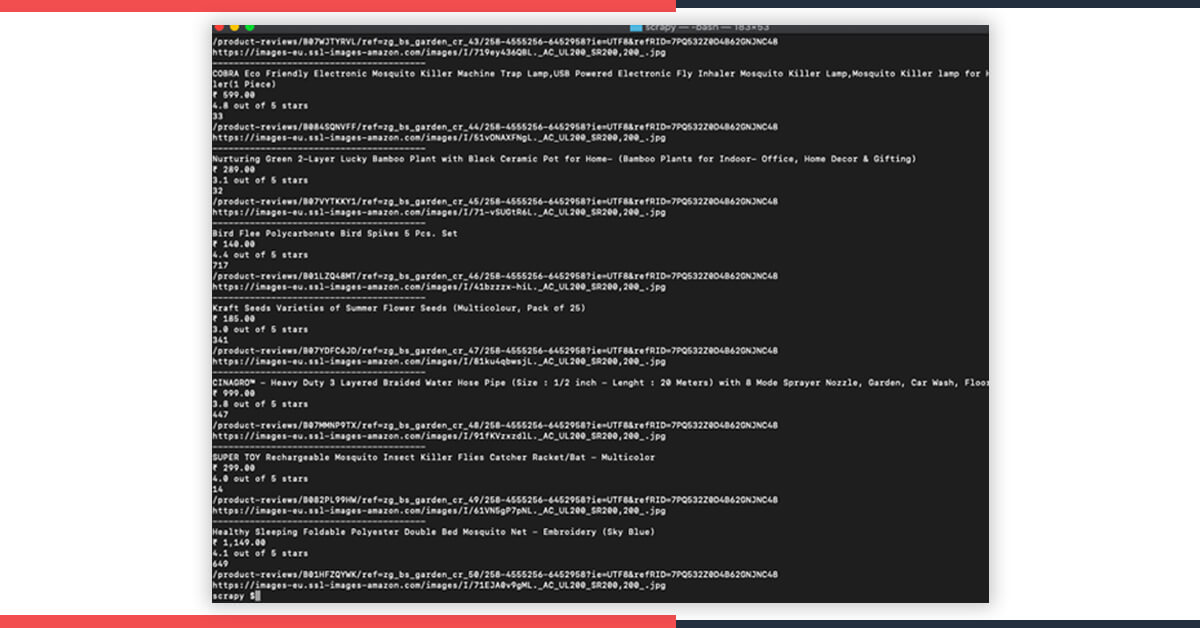
Here, we can select classes within the rows that have the necessary data.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url = 'https://www.amazon.in/gp/bestsellers/garden/ref=zg_bs_nav_0/258-0752277-9771203'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('.zg-item-immersion'):
try:
print('----------------------------------------')
print(item)
print(item.select('.p13n-sc-truncate')[0].get_text().strip())
print(item.select('.p13n-sc-price')[0].get_text().strip())
print(item.select('.a-icon-row i')[0].get_text().strip())
print(item.select('.a-icon-row a')[1].get_text().strip())
print(item.select('.a-icon-row a')[1]['href'])
print(item.select('img')[0]['src'])
except Exception as e:
#raise e
print('')
If you run it, that would print the information you have.
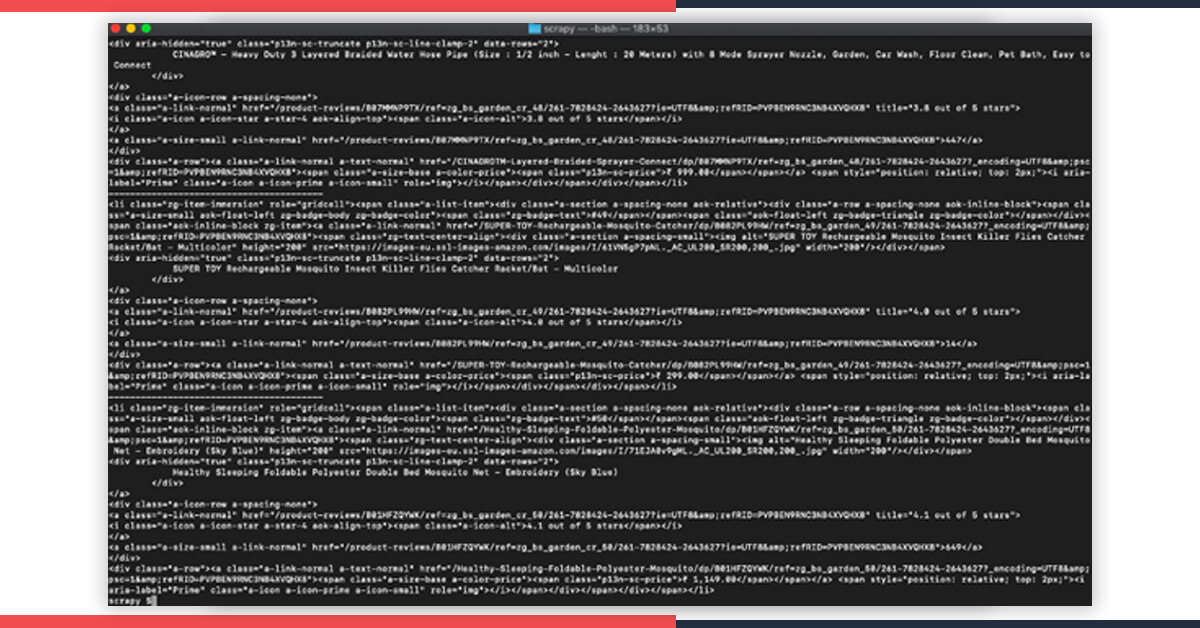
That’s it!! We have got the results.
If you want to use it in production and also want to scale millions of links then your IP will get blocked immediately. With this situation, the usage of rotating proxies for rotating IPs is a must. You may utilize services including Proxies APIs to route your calls in millions of local proxies.
If you want to scale the web scraping speed and don’t want to set any individual arrangement, then you may use RetailGators’ Amazon web scraper for easily scraping thousands of URLs at higher speeds.




Leave a Reply
Your email address will not be published. Required fields are marked