
Scrape Different Pages as well as Store Data in the Database
In the part 1, we extracted different items in the search results on Amazon.com as well as save them in the lists that you might create the data frame as well as save data in the CSV file. In this part, we will extract different pages as well as store them with relational database through sqlite3.
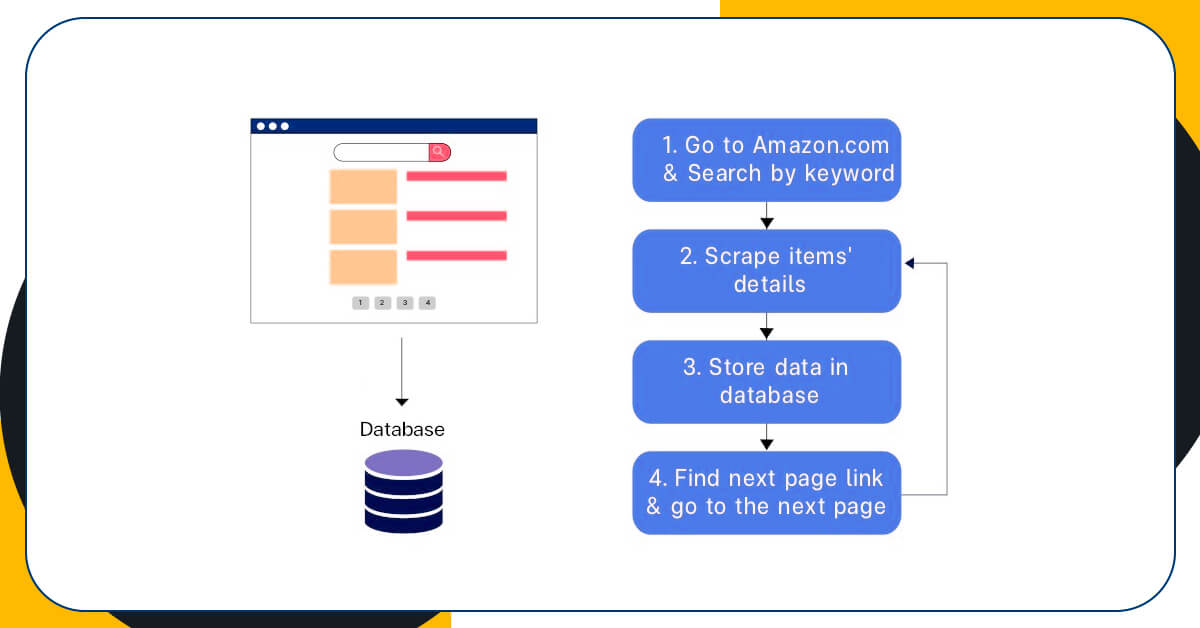
The brief procedures of web extraction in the tutorial is given in a diagram. After scraping items’ information on first page, we would store them within sqlite3 database. Therefore, the function called store_db was made.
import sqlite3
def store_db(product_asin, product_name, product_price, product_ratings, product_ratings_num, product_link):
conn = sqlite3.connect('amazon_search.db')
curr = conn.cursor()
# create table
curr.execute('''CREATE TABLE IF NOT EXISTS search_result (ASIN text, name text, price real, ratings text, ratings_num text, details_link text)''')
# insert data into a table
curr.executemany("INSERT INTO search_result (ASIN, name, price, ratings, ratings_num, details_link) VALUES (?,?,?,?,?,?)",
list(zip(product_asin, product_name, product_price, product_ratings, product_ratings_num, product_link)))
conn.commit()
conn.close()
After that, we require to get pagination button that is subsequent to our present page number to get links to the next page.
Get the next_page Element

At the bottom of the initial page, we review page 2 switch as given below.

As now we are at <li class=”a-selected”> , the subsequent page button would be following sibling that is also <li> tag as well as a link for next page gets stored as the values of attribute href about the child node <a> tags. The xpath for next_page component would be ‘//li[@class =”a-selected”]/following-sibling::li/a’
Enduring from part 1, after extracting a page, we could use a store_db function through data lists like parameters. After that, we use Selenium to find the subsequent page link. Although, as we are extracting different pages, the next_page link would get changed whenever we extract a page. So, we require to define a global variable named next_page which is equal to the empty string at the starting of a code.
next_page = ''
driver = webdriver.Chrome(options=options, executable_path=driver_path)
...
product_asin = []
product_name = []
product_price = []
product_ratings = []
product_ratings_num = []
product_link = []
items = wait(driver, 10).until(EC.presence_of_all_elements_located((By.XPATH, '//div[contains(@class, "s-result-item s-asin")]')))
for item in items:
...
# store data from lists to database
store_db(product_asin, product_name, product_price, product_ratings, product_ratings_num, product_link)
global next_page
next_page = driver.find_element_by_xpath('//li[@class ="a-selected"]/following-sibling::a').get_attribute("href")
Now, as we have completed code for extracting one page, wrap-up these codes in a function scrape_page as well as make the key extracting function name as scrape_amazon.
def scrape_amazon(keyword, max_pages):
page_number = 1
next_page = ''
driver = webdriver.Chrome(options=options, executable_path=driver_path)
driver.get(web)
driver.implicitly_wait(5)
keyword = keyword
search = driver.find_element_by_xpath('//*[(@id = "twotabsearchtextbox")]')
search.send_keys(keyword)
# click search button
search_button = driver.find_element_by_id('nav-search-submit-button')
search_button.click()
driver.implicitly_wait(5)
while page_number <= max_pages:
scrape_page(driver)
page_number += 1
driver.get(next_page)
driver.implicitly_wait(5)
driver.quit()
Run a function called scrape_amazon using keyword as well as max_pages required.
scrape_amazon('wireless charger',3)
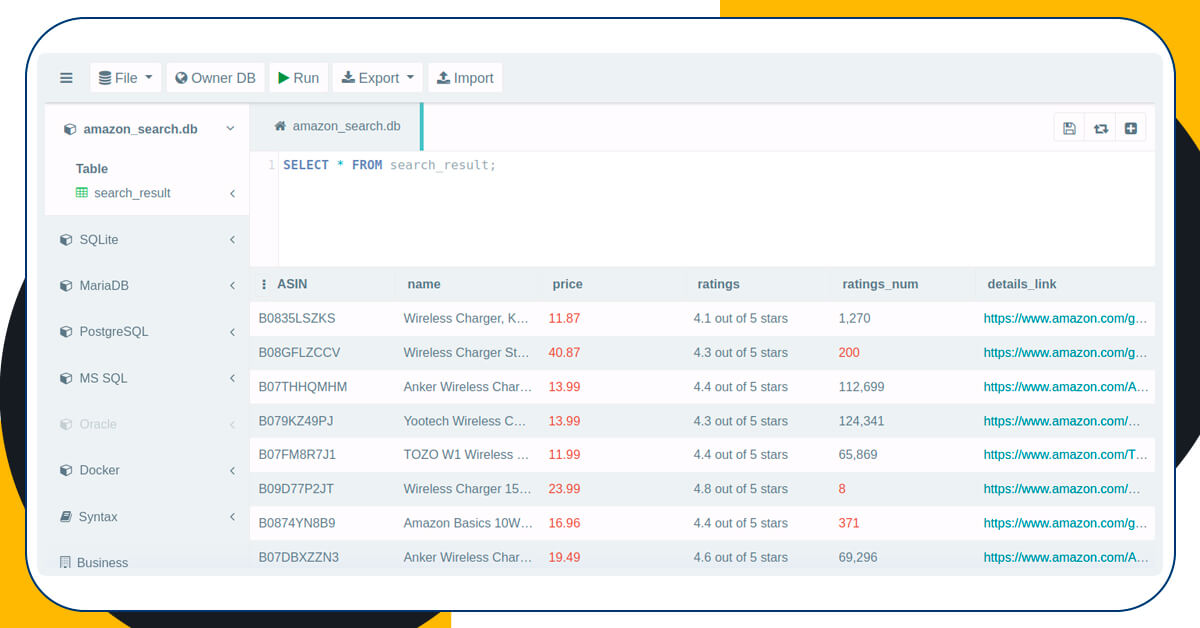
The amazon_search.db would emerge in the project folder. For opening the sqlite3 database, just utilize a program similar to DB Browser. Furthermore, you can get a quicker look through opening amazon_search.db (File > Open DB) as well as run the query on a website www.sqliteonline.com.
Note:
Some restrictions are there for scraping data together with the tutorial. Certain web elements could change the xpath completely. While writing the content, we had made some changes of a website’s structure. Though, if we take the basics of Selenium as well as HTML structure, then we would familiarize the code.
Conclusion
Many tools are there, which can perform web scraping. A few of them are more stable and appropriate to extract data from Amazon particularly when you need to scrape Amazon product data. Scraping with Selenium is quite challenging but that makes us study a lot more.
We end the part 2 here. In case of any query, you can contact Retailgators or ask for a free quote for Amazon product data scraping services.




Leave a Reply
Your email address will not be published. Required fields are marked