
Introduction
Amazon is a very well-known platform for buyers, sellers, as well as dealers.
Amazon has been progressive in the collection, storing, as well as analyzing a huge amount of data including product information, customer data, retailers’ data, or even general market trend data. As Amazon is amongst the biggest e-commerce sites, many firms and analysts rely on the scraped data from there to get actionable insights.
The booming e-commerce industry requires sophisticated analytical methods to forecast market trends, learn customer temperament, or get a viable edge over the leading players in the sector. To enhance the analytical strength, you require high-quality and reliable data.
The data is known as alternative data as well as could be taken from different sources. Amongst the key alternative data sources in the e-commerce industry include product information, customer reviews, and geographical data. All the e-commerce sites are a wonderful source for the data elements.
We all know that Amazon is the front-runner in the e-commerce business. Retailers fight very hard to extract data from Amazon. Although, Amazon data scraping is a very hard thing to do! Let’s discuss the key challenges that make Amazon data scraping a tedious job.
Why Scraping Data from Amazon is a Challenging Job
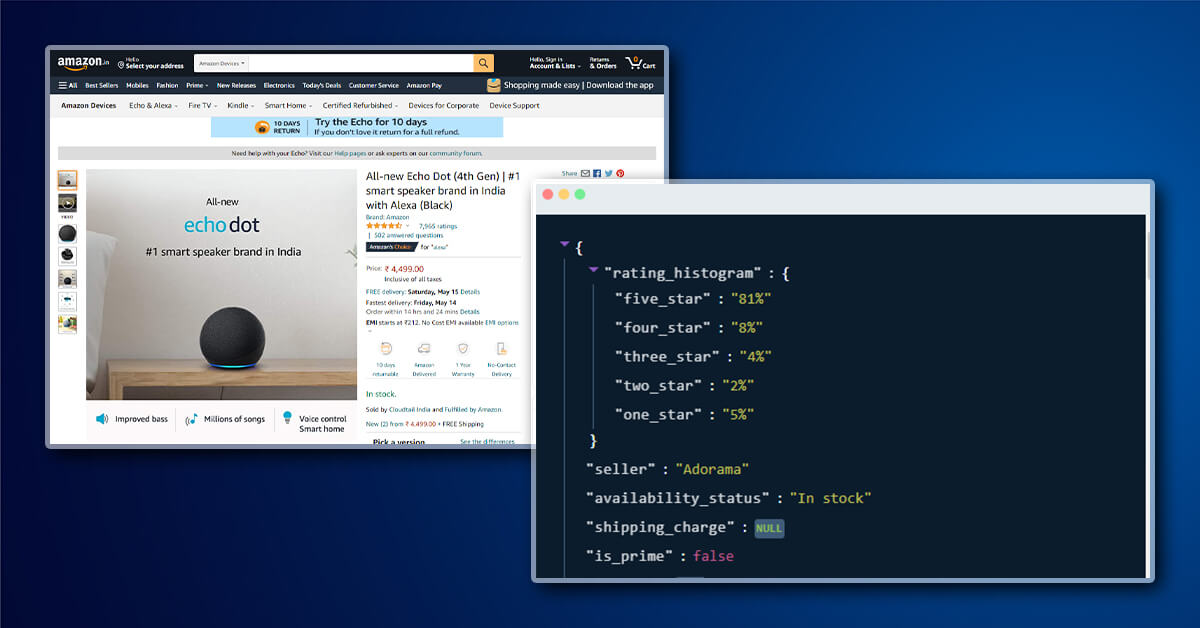
Before you begin Amazon data scraping, you need to know that a website depresses web scraping in the policy as well as page structure. Because of its consigned interest in defending its data, Amazon has some fundamental anti-scraping measures positioned. This could stop your Amazon web scraper from scraping all the data you want.
In addition, the page structure may or may not vary for different products. It might result in failing your Amazon data scraper code as well as logic. The worst scenario is that you may not even predict this problem springing up as well as may even run in a few network errors as well as unknown replies.
Moreover, captcha problems, as well as IP blocks, maybe a general roadblock. You would feel the requirement to have the database as well as lack of one could be a big problem!
You would also require to deal with exceptions when writing the algorithms for your Amazon web data scraper. This will become useful if you try to avoid problems because of difficult page structures, unusual characters, as well as other problems including vast memory requirements and funny URLs.
Let’s discuss some problems in detail. We should also understand how to resolve them. Optimistically, it will assist you in successfully scraping data from Amazon.
1. Amazon is Very Smart! It Can Identify Bots as well as Block the IPs

As Amazon stops web data scraping on the pages, it could easily identify if any action is taken by a web scraper or using a browser through a manual proxy. Most of these styles are recognized by carefully monitoring the browsing agent’s behavior.
For instance, if the URLs are changed repeatedly by query parameters at the regular interval, it is a clear sign of a data scraper going through a page. Thus, it uses captchas as well as IP bans for blocking these bots. As this step is required to protect the integrity and privacy of information, one may still require scraping Amazon product data. To perform that, we have a few workarounds.
Let us observe some of them:
- Alter scraper headers for making it look like requests are approaching from the browser as well as not the piece of code.
- Encourage random time gaps as well as pauses within the scraper code for breaking the consistency of the page triggers.
- Remove query constraints from URLs for removing identifiers link requests together.
- Rotate IPs with various proxy servers in case you require to. You may also utilize consumer-grade VPN services using IP rotation abilities.
2. Many Amazon Pages Have Special Page Structures
In case, you have tried to scrape Amazon product descriptions and extract data from Amazon, you could have run into many unidentified response exceptions and errors. It’s because the majority of web scrapers are designed as well as customized for any particular page structure. This is used for following any special page structure, scrape HTML data, as well as collect the required data. Although, if the page structure changes, the data scraper might fail in case it is not well-prepared to deal with exceptions.
Many Amazon products have a lot of pages and attributes about these pages that differ from the standard template. It is usually done to deal with different kinds of products, which may have various features and key attributes that require getting highlighted. For addressing these inconsistencies, you need to write a code to deal with exceptions.
Moreover, your code needs to be resistant. You may do it by including the ‘try-catch’ phrases, which make sure that a code does not fail with the first occurrences of the network errors or time-out errors. As you would be scraping a few particular product attributes, you could design a code so that a web scraper may look for the particular attributes using the tools including ‘string matching’. You may do that after scraping the whole HTML structure for the targeted page.
3. Your Web Scraper Might not be Proficient Enough!

Ever got the web scraper, which has been running time to get some thousands of rows? It could be as you haven’t dealt with the speed and efficiency of the algorithms. You may do some fundamental math when designing the algorithms.
Let us observe what you could do for solving the problem! You would always need the number of sellers or products to scrape Amazon data. Using data, you may roughly calculate the total requests you require to send each second for completing your web scraping exercise. When you compute that, your objective is to design a data scraper for meeting this condition!
A single-threaded network block operations would fail in case, you wish to speed up things! Probably, you might want to make multi-threaded data scrapers! It permits CPU to effort in the parallel fashion! This will work on one reply or another when every request takes several seconds for completion. This could provide you nearly 100x of the speed of the original single-threaded web scraper! You will require a well-organized Amazon data scraper to scrape Amazon data because there are a lot of data on the website!
4. A Cloud Platform is Needed with Other Computational Support!

Any high-performance machine would speed up the procedure for you! This you can avoid burning the sources of your domestic system! To scrape data from Amazon, you may require higher capacity memory sources! You would also require network pipes as well as cores using higher efficiency! A cloud-based platform needs to be able to offer these sources!
You do not need to go into memory problems! In case, you are storing big dictionaries or lists in the memory, you may put extra burdens on the machine sources! We counsel you to change your data for permanent storage as quickly as possible. It will also assist you in speeding up the procedure.
There are many cloud services, which you can utilize at affordable prices. You may get these services using easy steps. This will assist you in avoiding needless system crashes as well as delays in the procedure.
5. Using a Database to Record Information

In case, you extract data from Amazon as well as other e-commerce websites, you would be getting higher data volumes. As the procedure of extraction consumes time and power, we recommend you store data in the database.
Storing every sellers’ or products’ record, which you scrape as the row in the database table. Also, you may use databases for performing operations including basic querying, exports, and presuming your data. It makes the procedure of analyzing, storing, as well as reusing the data suitably and quicker!
Summary
Many analysts and businesses, particularly in the e-commerce and retail sector require Amazon data scraping. They utilize this data for making price comparisons, study market trends for demographics, forecast product sales, review customers’ sentiments or even estimate competition rates. It can be a tedious exercise. In case, you make your own Amazon web scraper, it could be a challenging and time-consuming process.
RetailGators can extract e-commerce product data from an extensive range of data sources and offer data in readable formats including ‘CSV’ and other locations according to clients’ requirements. Then you can utilize data for subsequent analyses. It will assist you in saving time and resources. We recommend you organize detailed research on different web scraping services available in the market. Then you can avail the services, which suit your requirements in the best possible manner.




Leave a Reply
Your email address will not be published. Required fields are marked